Publicly released exploit code for an effectively unpatched vulnerability that gives root access to virtually all releases of Linux is setting off alarm bells as defenders scramble to ward off severe compromises inside data centers and on personal devices.
The vulnerability and exploit code that exploits it were released Wednesday evening by researchers from security firm Theori, five weeks after privately disclosing it to the Linux kernel security team. The team patched the vulnerability in versions 7.0, 6.19.12, 6.18.12, 6.12.85, 6.6.137, 6.1.170, 5.15.204, and 5.10.254) but few of the Linux distributions had incorporated those fixes at the time the exploit was released.
A single script hacks all distros
The critical flaw, tracked as CVE-2026-31431 and the name CopyFail, is a local privilege escalation, a vulnerability class that allows unprivileged users to elevate themselves to administrators. CopyFail is particularly severe because it can be exploited with a single piece of exploit code—released in Wednesday’s disclosure—that works across all vulnerable distributions with no modification. With that, an attacker can, among other things, hack multi-tenant systems, break out of containers based on Kubernetes or other frameworks, and create malicious pull requests that pipe the exploit code through CI/CD work flows.
This April, Hong Kong-based DAIMON Robotics has released Daimon-Infinity, which it describes as the largest omni-modal robotic dataset for physical AI, featuring high resolution tactile sensing and spanning a wide range of tasks from folding laundry at home to manufacturing on factory assembly lines. The project is supported by collaborative efforts of partners across China and the globe, including Google DeepMind, Northwestern University, and the National University of Singapore.
The move signals a key strategic initiative for DAIMON, a two-and-a-half-year-old company known for its advanced tactile sensor hardware, most notably a monochromatic, vision-based tactile sensor that packs over 110,000 effective sensing units into a fingertip-sized module. Drawing on its high-resolution tactile sensing technology and a distributed out-of-lab collection network capable of generating millions of hours of data annually, DAIMON is building large-scale robot manipulation datasets that include vast amounts of tactile sensing data. To accelerate the real-world deployment of embodied AI, the company has also open-sourced 10,000 hours of its data.
Prof. Michael Yu Wang, co-founder and chief scientist at DAIMON Robotics, has pioneered Vision-Tactile-Language-Action (VTLA) architecture, elevating the tactile to a modality on par with vision.DAIMON Robotics
Behind the strategy is Prof. Michael Yu Wang, DAIMON’s co-founder and chief scientist. Prof. Wang earned his PhD at Carnegie Mellon — studying manipulation under Matt Mason — and went on to found the Robotics Institute at the Hong Kong University of Science and Technology. An IEEE Fellow and former Editor-in-Chief of IEEE Transactions on Automation Science and Engineering, he has spent roughly four decades in the field. His objective is to address the missing “insensitivity” of robot manipulation, which practically relies on the dominant Vision-Language-Action (VLA) model. He and his team have pioneered Vision-Tactile-Language-Action (VTLA) architecture, elevating the tactile to a modality on par with vision.
We spoke with Prof. Wang about how tactile feedback aims to change dexterous manipulation, how the dataset initiative is foreseen to improve our understanding of robotic hands in natural environments, and where — from hotels to convenience stores in China — he sees touch-enabled robots making their first real-world inroads.
Daimon-Infinity is the world’s largest omni-modal dataset for Physical AI, featuring million-hour scale multimodal data, ultra-high-res tactile feedback, data from 80+ real scenarios and 2,000+ human skills, and more.DAIMON Robotics
The Dataset Initiative
Thismonth, DAIMON Roboticsreleased the largest and most comprehensive robotic manipulation dataset with multiple leading academic institutions and enterprises. Why releasing the dataset now, rather than continuing to focus on productdevelopment? What impact will this have on the embodied intelligence industry?
DAIMON Robotics has been around for almost two and a half years. We have been committed to developing high-resolution, multimodal tactile sensing devices to perceive the interaction between a robot’s hand (particularly its fingertips) and objects. Our devices have become quite robust. They are now accepted and used by a large segment of users, including academic and research institutes as well as leading humanoid robotics companies.
As embodied AI continues to advance, the critical role of data has been clearer. Data scarcity remains a primary bottleneck in robot learning, particularly the lack of physical interaction data, which is essential for robots to operate effectively in the real world. Consequently, data quality, reliability, and cost have become major concerns in both research and commercial development.
This is exactly where DAIMON excels. Our vision-based tactile technology captures high-quality, multimodal tactile data. Beyond basic contact forces, it records deformation, slip and friction, material properties and surface textures — enabling a comprehensive reconstruction of physical interactions. Building on our expertise in multimodal fusion, we have developed a robust data processing pipeline that seamlessly integrates tactile feedback with vision, motion trajectories, and natural language, transforming raw inputs into training-ready dataset for machine learning models.
Recognizing the industry-wide data gap, we view large-scale data collection not only as our unique competitive advantage, but as a responsibility to the broader community.
By building and open-sourcing the dataset, we aim to provide the high-quality “fuel” needed to power embodied AI, ultimately accelerating the real-world deployment of general-purpose robotic foundation models.
The robotics industry is highly competitive, and many teams have chosen to focus on data. DAIMON is releasing a large and highly comprehensive cross-embodiment, vision-based tactile multimodal robotic manipulation dataset. How were you able to achieve this?
We have a dedicated in-house team focused on expanding our capabilities, including building hardware devices and developing our own large-scale model. Although we are a relatively small company, our core tactile sensing technology and innovative data collection paradigm enable us to build large-scale dataset.
Our approach is to broaden our offering. We have built the world’s largest distributed out-of-lab data collection network. Rather than relying on centralized data factories, this lightweight and scalable system allows data to be gathered across diverse real-world environments, enabling us to generate millions of hours of data per year.
“To drive the advancement of the entire embodied AI field, we have open-sourced 10,000 hours of the dataset for the broader community.” —Prof. Michael Yu Wang, DAIMON Robotics
This dataset is being jointlydeveloped with several institutionsworldwide. What roles did they play in its development, and how will the dataset benefit their research and products?
Besides China based teams, our partners include leading research groups from universities, such as Northwestern University and the National University of Singapore, as well as top global enterprises like Google DeepMind and China Mobile. Their decision to partner with DAIMON is a strong testament to the value of our tactile-rich dataset.
Among the companies involved there are some that have already built their own models but are now incorporating tactile information. By deploying our data collection devices across research, manufacturing and other real-world scenarios, they help us to gather highly practical, application-driven data. In turn, our partners leverage the data to train models tailored to their specific use cases. Furthermore, to drive the advancement of the entire embodied AI field, we have open-sourced 10,000 hours of the dataset for the broader community.
Equipped with Daimon’s visuotactile sensor, the gripper delicately senses contact and precisely controls force to pick up a fragile eggshell.Daimon Robotics
From VLA to VTLA: Why Tactile Sensing Changes the Equation
The mainstream paradigm in robotics is currently the Vision-Language-Action (VLA) model, but your team has proposed a Vision-Tactile-Language-Action (VTLA) model. Why is it necessary to incorporate tactile sensing? What does it enable robots to achieve, and which tasks are likely to fail without tactile feedback?
Over these years of working to make generalist robots capable of performing manipulation tasks, especially dexterous manipulation — not just power grasping or holding an object, but manipulating objects and using tools to impart forces and motion onto parts — we see these robots being used in household as well as industrial assembly settings.
It is well established that tactile information is essential for providing feedback about contact states so that robots can guide their hands and fingers to perform reliable manipulation. Without tactile sensing, robots are severely limited. They struggle to locate objects in dark environments, and without slip detection, they can easily drop fragile items like glass. Furthermore, the inability to precisely control force often leads to failed manipulation tasks or, in severe cases, physical damage. Naturally, the VLA approach needs to be enhanced to incorporate tactile information. We expanded the VLA framework to incorporate tactile data, creating the VTLA model.
An additional benefit of our tactile sensor is that it is vision-based: We capture visual images of the deformation on the fingertip surface. We capture multiple images in a time sequence that encodes contact information, from which we can infer forces and other contact states. This aligns well with the visual framework that VLA is based upon. Having tactile information in a visual image format makes it naturally suitable for integration into the VLA framework, transforming it into a VTLA system. That is the key advantage: Vision-based tactile sensors provide very high resolution at the pixel level, and this data can be incorporated into the framework, whether it is an end-to-end model or another type of architecture.
DAIMON has been known for its vision-based tactile sensors that can pack over 110,000 effective sensing units.DAIMON Robotics
The Technology: Monochromatic Vision-based Tactile Sensing
You and your team have spent many years deeply engaged in vision-based tactile sensing and have developed the world’s first monochromatic vision-based tactile sensing technology. Why did you choose this technical path?
Once we started investigating tactile sensors, we understood our needs. We wanted sensors that closely mimic what we have under our fingertip skin. Physiological studies have well documented the capabilities humans have at their fingertips — knowing what we touch, what kind of material it is, how forces are distributed, and whether it is moving into the right position as our brain controls our hands. We knew that replicating these capabilities on a robot hand’s fingertips would help considerably.
When we surveyed existing technologies, we found many types, including vision-based tactile sensors with tri-color optics and other simpler designs. We decided to integrate the best of these into an engineering-robust solution that works well without being overly complicated, keeping cost, reliability, and sensitivity within a satisfactory range, thus ultimately developing a monochromatic vision-based tactile sensing technique. This is fundamentally an engineering approach rather than a purely scientific one, since a great deal of foundational research already existed. With the growing realization of the necessity of tactile data, all of this will advance hand in hand.
Last year, DAIMON launched a multi-dimensional, high-resolution, high-frequency vision-based tactile sensor. Compared with traditional tactile sensors, where does its core advantage lie? Which industries could it potentially transform?
The key features of our sensors are the density of distributed force measurement and the deformation we can capture over the area of a fingertip. I believe we have the highest density in terms of sensing units. That is one very important metric. The other is dynamics: the frequency and bandwidth — how quickly we can detect force changes, transmit signals, and process them in real time. Other important aspects are largely engineering-related, such as reliability, drift, durability of the soft surface, and resistance to interference from magnetic, optical, or environmental factors.
A growing number of researchers and companies are recognizing the importance of tactile sensing and adopting our technology. I believe the advances in tactile sensing will elevate the entire community and industry to a higher level. One of our potential customers is deploying humanoid robots in a small convenience store, with densely packed shelves where shelf space is at a premium. The robot needs to reach into very tight spaces — tighter than books on a shelf — to pick out an object. Current two-jaw parallel grippers cannot fit into most of these spaces. Observing how humans pick up objects, you clearly need at least three slim fingers to touch and roll the object toward you and secure it. Thus, we are starting to see very specific needs where tactile sensing capabilities are essential.
From Academia to Startup
After 40 years in academia — founding the HKUST Robotics Institute, earning prestigious honors including IEEE Fellow, and serving as Editor-in-Chief of IEEE TASE — what motivated you to found DAIMON Robotics?
I have come a long way. I started learning robotics during my PhD at Carnegie Mellon, where there were truly remarkable groups working on locomotion under Marc Raibert, who founded Boston Dynamics, and on manipulation under my advisor, Matt Mason, a leader in the field. We have been working on dexterous manipulation, not only at Carnegie Mellon, but globally for many years.
However, progress has been limited for a long time, especially in building dexterous hands and making them work. Only recently have locomotion robots truly taken off, and only in the last few years have we begun to see major advancements in robot hands. There is clearly room for advancing manipulation capabilities, which would enable robots to do work like humans. While at Hong Kong University of Science and Technology, I saw increasingly greater people entering this area in the form of students and postdoctoral researchers. We wanted to jumpstart our effort by leveraging the available capital and talent resources.
Fortunately, one of my postdocs, Dr. Duan Jianghua, has a strong sense for commercial opportunities. Recognizing the rapid growth of robotics market and the unique value that our vision-based tactile sensing technology could bring, together we started DAIMON Robotics, and it has progressed well. The community has grown tremendously in China, Japan, Korea, the U.S., and Europe.
Robots equipped with DAIMON technology have been deployed in factory settings. The company aims to enable robots to achieve “embodied intelligence” and close the gap between what they can see and what they can feel.DAIMON Robotics
Business Model and Commercial Strategy
What is DAIMON’s current business model and strategic focus? What role does the dataset release play in your commercial strategy?
We started as a device company focused on making highly capable tactile sensors, especially for robot hands. But as technology and business developed, everyone realized it is not just about one component, rather the entire technology chain: devices, data of adequate quality and quantity, and finally the right framework to build, train, and deploy models on robots in real application environments.
Our business strategy is best described as “3D”: Devices, Data, and Deployment. We build devices for data collection, our own ecosystem, and for deploying them in our partners’ potential application domains. This enables the collection of real-world tactile-rich data and complete closed-loop validation. This will become an integral part of the 3D business model. Most startups in this space are following a similar path until eventually some may become more specialized or more tightly integrated with other companies. For now, it is mostly vertical integration.
Embodied Skills and the Convergence Moment
You’ve introduced the concept of “embodied skills” as essential for humanoid robots to move beyond having just an advanced AI “brain.” What prompted this insight? What new capabilities could embodied skills enable? After the rapid evolution of models and hardware over the past two years, has your definition or roadmap for embodied skills evolved?
We have come a long way now see a convergence point where electrical, electronic, and mechatronic hardware technologies have advanced tremendously in last two decades. Robots are now fully electric, do not require hydraulics, because hardware has evolved rapidly. Modern electronics provide tremendous bandwidth with high torques. If we can build intelligence into these systems, we can create truly humanoid robots with the ability to operate in unstructured environments, make decisions, and take actions autonomously.
“Our vision is for robots to achieve robust manipulation capabilities and evolve into reliable partners for humans.” —Prof. Michael Yu Wang, DAIMON Robotics
AI has arrived at exactly the right time. Enormous resources have been invested in AI development, especially large language models, which are now being generalized into world models that enable physical AI capabilities. We would like to see these manifested in real-world systems.
While both AI and core hardware technologies continue to evolve, the focus is much clearer now. For example, human-sized robots are preferred in a home environment. This is an exciting domain with a promise of great societal benefit if we can eventually achieve safe, reliable, and cost-effective robots.
The Road to Real-World Deployment
Today, many robots can deliver impressive demos, yet there remains a gap before they truly enter real-world applications. What could be a potential trigger for real-world deployment? Which scenarios are most likely to achieve large-scale deployment first?
I think the road toward large-scale deployment of generalist robots is still long, but we are starting to see signs of feasibility within specific domains. It is very similar to autonomous vehicles, where we are yet to see full deployment of robo-taxis, while we have already started to find mobile robots and smaller vehicles widely deployed in the hospitality industry. Virtually every major hotel in China now has a delivery robot — no arms, just a vehicle that picks up items from the hotel lobby (e.g., food deliveries). The delivery person just loads the food and selects the room number. It is up to the robot thereafter to navigate and reach the guest’s room, which includes using the elevator, to deliver the food. This is already nearly 100 percent deployed in major Chinese hotels.
Hotel and restaurant robots are viewed as a model for deploying humanoid robots in specific domains like overnight drugstores and convenience stores. I expect complete deployment in such settings within a short timeframe, followed by other applications. Overall, we can expect autonomous robots, including humanoids, to progressively penetrate specific sectors, delivering value in each and expanding into others.
Ultimately, our vision is for robots to achieve robust manipulation capabilities and evolve into reliable partners for humans. By seamlessly integrating into our homes and daily lives, they will genuinely benefit and serve humanity.
This interview has been edited for length and clarity.
Laboratory or in-field measurements are often considered the gold standard for certain aspects of power system design; however, measurement approaches always have limitations. Simulation can help overcome some of these limitations, including speeding up the design process, reducing design costs, and assessing situations that are often not feasible to measure directly. In this presentation, we will discuss two examples from the power system industry.
The first case we will discuss involves corona performance testing of high-voltage transmission line hardware. Corona-free insulator hardware performance is critical for operation of transmission lines, particularly at 500 kV, 765 kV, or higher voltages. Laboratory mockups are commonly used to prove corona performance, but physical space constraints usually restrict testing to a partial single-phase setup. This requires establishing equivalence between the laboratory setup and real-world three-phase conditions. In practice, this can be difficult to do, but modern simulation capabilities can help. The second case involves submarine HVDC cables, which are commonly used for offshore wind interconnects. HVDC cables are often considered to be environmentally inert from an external electric field perspective (i.e., electric fields are contained in the cable, and the cable’s static magnetic fields induce no voltages externally). However, simulation demonstrates that ocean currents moving through the static magnetic field satisfy the relative motion requirement of Faraday’s law. Thus, externally induced electric fields can exist around the cable and are within a range detectable by various aquatic species.
Key Takeaway:
Learn how to use modern simulation to translate single-phase laboratory corona mockups into accurate three-phase real-world performance for 500 kV and 765 kV systems.
Explore the physics behind how ocean currents interacting with HVDC submarine cables create induced electric fields—a phenomenon often overlooked but detectable by aquatic species.
Gain actionable insights into how to leverage simulation to reduce design costs and bypass the physical space constraints that often stall traditional testing.
See a practical application of electromagnetic theory as we demonstrate how relative motion in static magnetic fields necessitates simulation where direct measurement is unfeasible.
Think one GPU is very much like another? Think again. It turns out that there’s surprising variability in the performance delivered by chips of the same model. That can make getting your money’s worth by renting time on a GPU from a cloud provider a real roll of the dice, according to research from the College of William & Mary, Jefferson Lab, and Silicon Data.
“It’s called the silicon lottery,” says Carmen Li, founder and CEO of Silicon Data, which tracks GPU rental prices and benchmarks cloud-computing performance.
The silicon lottery’s existence has been known since at least 2022, when researchers at the University of Wisconsin tied it to variations in the performance of GPU-dependent supercomputers. Li and her colleagues figured that the effect would be even more pronounced for AI cloud customers.
Performance varies for GPU models in the cloud
So they ran 6,800 instances of the index firm’s benchmark test on 3,500 randomly selected GPUs operated by 11 cloud-computing providers. The 3,500 GPUs comprised 11 models of Nvidia GPU, the most advanced being the Nvidia H200 SXM. (The team wasn’t just picking on Nvidia; the GPU giant makes up most of the rental cloud market.)
The benchmark, called SiliconMark, is intended to provide a snapshot of a GPU’s ability to run large language models, or LLMs. It tests 16-bit floating-point computing performance, measured in trillions of operations per second, and a GPU’s internal-memory bandwidth, measured in gigabytes per second. The results showed that the computing performance varied for all models, but for the 259 H100 PCIe GPUs it differed by as much as 34.5 percent, and the memory bandwidth of the 253 H200 SXM GPUs varied by as much as 38 percent.
Differences in how the GPU is cooled, how cloud operators configure their computers, and how much use the chip has seen can all contribute to variations in performance of otherwise identical chips. But Silicon Data’s analysis showed that the real culprit was variations in the chips themselves, likely due to manufacturing issues.
Such randomness has real dollars-and-cents consequences, the researchers argue, because there’s a chance that a pricier, more advanced GPU won’t deliver better performance than an older model chip.
So what should GPU renters do? “The most practical approach is to benchmark the actual rental they receive,” says Jason Cornick, head of infrastructure at Silicon Data. “Running a benchmark tool [such as SiliconMark] allows them to compare their specific instance’s performance against a broader corpus of data.”
It has been a bad six weeks for security firm Checmarx. Over the past 40 days, it has been the victim of at least one supply-chain attack that delivered malware to customers on two separate occasions. Now it has been hit by a ransomware attack from prolific fame-seeking hackers.
The streak of misfortunes started on March 19, with the supply-chain attack of Trivy, a widely used vulnerability scanner. The attackers behind the breach first breached the Trivy GitHub account and then used their access to push malware to Trivy users, one of which was Checkmarx. The pushed malware scoured infected machines for repository tokens, SSH keys, and other credentials.
Both a target and delivery mechanism
Four days later, Checkmarx’s GitHub account was compromised and began pushing malware to the security firm’s users. The company contained and remediated the breach and replaced the malware with the legitimate apps. Or so Checkmarx thought.
On 12 March, an IEEE Milestone plaque recognizing the first FPGA was dedicated at the Advanced Micro Devices campus in San Jose, Calif., the former Xilinx headquarters and the birthplace of the technology.
The FPGA earned the Milestone designation because it introduced iteration to semiconductor design. Engineers could redesign hardware repeatedly without fabricating a new chip, dramatically reducing development risk and enabling faster innovation at a time when semiconductor costs were rising rapidly.
The ceremony, which was organized by the IEEE Santa Clara Valley Section, brought together professionals from across the semiconductor industry and IEEE leadership. Speakers at the event included Stephen Trimberger, an IEEE and ACM Fellowwhose technical contributions helped shape modern FPGA architecture. Trimberger reflected on how the invention enabled software-programmable hardware.
FPGAs emerged in the 1980s to address a core limitation in computing. A microprocessor executes software instructions sequentially, making it flexible but sometimes too slow for workloads requiring many operations at once.
At the other extreme, application-specific integrated circuits are chips designed to do only one task. ASICs achieve high efficiency but require lengthy development cycles and nonrecurring engineering costs, which are large, upfront investments. Expenses include designing the chip and preparing it for manufacturing—a process that involves creating detailed layouts, building masks for the fabrication machines, and setting up production lines to handle the tiny circuits.
“ASICs can deliver the best performance, but the development cycle is long and the nonrecurring engineering cost can be very high,” says Jason Cong, an IEEE Fellow and professor of computer science at the University of California, Los Angeles. “FPGAs provide a sweet spot between processors and custom silicon.”
Cong’s foundational work in FPGA design automation and high-level synthesis transformed how reconfigurable systems are programmed. He developed synthesis tools that translate C/C++ into hardware designs, for example.
At the heart of his work is an underlying principle first espoused by electrical engineer Ross Freeman: By configuring hardware using programmable memory embedded inside the chip, FPGAs combine hardware-level speed with the adaptability traditionally associated with software.
Silicon Valley origins: the first FPGA
The FPGA architecture originated in the mid-1980s at Xilinx, a Silicon Valley company founded in 1984. The invention is widely credited to Freeman, a Xilinx cofounder and the startup’s CTO. He envisioned a chip with circuitry that could be configured after fabrication rather than fixed permanently during creation.
Articles about the history of the FPGA emphasize that he saw it as a deliberate break from conventional chip design.
At the time, semiconductor engineers treated transistors as scarce resources. Custom chips were carefully optimized so that nearly every transistor served a specific purpose.
Freeman proposed a different approach. He figured Moore’s Law would soon change chip economics. The principle holds that transistor counts roughly double every two years, making computing cheaper and more powerful. Freeman posited that as transistors became abundant, flexibility would matter more than perfect efficiency.
He envisioned a device composed of programmable logic blocks connected through configurable routing—a chip filled with what he described as “open gates,” ready to be defined by users after manufacturing. Instead of fixing hardware in silicon permanently, engineers could configure and reconfigure circuits as requirements evolved.
Freeman sometimes compared the concept to a blank cassette tape: Manufacturers would supply the medium, while engineers determined its function. The analogy captured a profound shift in who controls the technology, shifting hardware design flexibility from chip fabrication facilities to the system designers themselves.
In 1985 Xilinx introduced the first FPGA for commercial sale: the XC2064. The device contained 64 configurable logic blocks—small digital circuits capable of performing logical operations—arranged in an 8-by-8 grid. Programmable routing channels allowed engineers to define how signals moved between blocks, effectively wiring a custom circuit with software.
Fabricated using a 2-micrometer process (meaning that 2 µm was the minimum size of the features that could be patterned onto silicon using photolithography), the XC2064 implemented a few thousand logic gates. Modern FPGAs can contain hundreds of millions of gates, enabling vastly more complex designs. Yet the XC2064 established a design workflow still used today: Engineers describe the hardware behavior digitally and then “compile the design,” a process that automatically translates the plans into the instructions the FPGA needs to set its logic blocks and wiring, according to AMD. Engineers then load that configuration onto the chip.
The breakthrough: hardware defined by memory
Earlier programmable logic devices, such as erasable programmable read-only memory, or EPROM, allowed limited customization but relied on largely fixed wiring structures that did not scale well as circuits grew more complex, Cong says.
FPGAs introduced programmable interconnects—networks of electronic switches controlled by memory cells distributed across the chip. When powered on, the device loads a bitstream configuration file that determines how its internal circuits behave.
“As process technology improved and transistor counts increased, the cost of programmability became much less significant,” Cong says.
From “glue logic” to essential infrastructure
“Initially, FPGAs were used as what engineers called glue logic,” Cong says.
Glue logic refers to simple circuits that connect processors, memory, and peripheral devices so the system works reliably, according to PC Magazine. In other words, it “glues” different components together, especially when interfaces change frequently.
Those uses revealed a broader shift: Hardware no longer needed to remain fixed once deployed.
Attendees at the Milestone plaque dedication ceremony included (seated L to R) 2025 IEEE President Kathleen Kramer, 2024 IEEE President Tom Coughlin, and Santa Clara Valley Section Milestones Chair Brian Berg.Douglas Peck/AMD
Semiconductor economics changed the equation
The rise of FPGAs closely followed changes in semiconductor economics, Cong says.
Developing a custom chip requires a large upfront investment before production begins. As fabrication costs increased, products had to ship in large quantities to make ASIC development economically viable, according to a post published by AnySilicon.
FPGAs allowed designers to move forward without that larger monetary commitment.
ASIC development typically requires 18 to 24 months from conception to silicon, while FPGA implementations often can be completed within three to six months using modern design tools, Cong says. The shorter cycle and the ability to reconfigure the hardware enabled startups, universities, and equipment manufacturers to experiment with advanced architectures that were previously accessible mainly to large chip companies.
Lookup tables and the rise of reconfigurable computing
Instead of repeatedly recalculating outcomes, the chip retrieves answers directly from memory. Cong compares the approach to consulting multiplication tables rather than recomputing the arithmetic each time.
Research led by Cong and others helped develop efficient methods for mapping digital circuits onto LUT-based architectures, shaping routing and layout strategies used in modern devices.
As transistor budgets expanded, FPGA vendors integrated memory blocks, digital signal-processing units, high-speed communication interfaces, cryptographic engines, and embedded processors, transforming the devices into versatile computing platforms.
Why the gate arrays are distinct from CPUs, GPUs, and ASICs
FPGAs coexist with other processors because each one optimizes different priorities. Central processing units excel at general computing. Graphics processing units, designed to perform many calculations simultaneously, dominate large parallel workloads such as AI training. ASICs provide maximum efficiency when designs remain stable and production volumes are high.
“ASICs can deliver the best performance, but the development cycle is long, and the nonrecurring engineering cost can be very high. FPGAs provide a sweet spot between processors and custom silicon.” —Jason Cong, IEEE Fellow and professor of computer science at UCLA.
“FPGAs are not replacements for CPUs or GPUs,” Cong says. “They complement those processors in heterogeneous computing systems.”
Modern computing platforms increasingly combine multiple types of processors to balance flexibility, performance, and energy efficiency.
A Milestone for an idea, not just a device
This IEEE Milestone recognizes more than a successful semiconductor product. It also acknowledges a shift in how engineers innovate.
Reconfigurable hardware allows designers to test ideas quickly, refine architectures, and deploy systems while standards and markets evolve.
“Without FPGAs,” Cong says, “the pace of hardware innovation would likely be much slower.”
Four decades after the first FPGA appeared, the technology’s enduring legacy reflects Freeman’s insight: Hardware did not need to remain fixed. By accepting a small amount of unused silicon in exchange for adaptability, engineers transformed chips from static products into platforms for continuous experimentation—turning silicon itself into a medium engineers could rewrite.
“The FPGA is an integrated circuit with user-programmable Boolean logic functions and interconnects. FPGA inventor Ross Freeman cofounded Xilinx to productize his 1984 invention, and in 1985 the XC2064 was introduced with 64 programmable 4-input logic functions. Xilinx’s FPGAs helped accelerate a dramatic industry shift wherein ‘fabless’ companies could use software tools to design hardware while engaging ‘foundry’ companies to handle the capital-intensive task of manufacturing the software-defined hardware.”
Administered by the IEEE History Center and supported by donors, the IEEE Milestone program recognizes outstanding technical developments worldwide that are at least 25 years old.
Check out Spectrum’s History of Technology channel to read more stories about key engineering achievements.
It started with word, cave, and storytelling, A line scratched on stone walls: “Meet me when the young moon rises.” The first protocol for connection.
Coyote tales, forbidden scripts, Medieval texts hidden from flame. What lived in Aristotle’s lostPoetics II? Was it God who laughed last, or we who made God laugh?
Letters carried by doves, telepathic waves. Then Nikola Tesla conjured radio, electromagnetic pulses across the void, the founding signal of our networked age.
Wiener dreamed in feedback loops. Shannon mapped the mathematics of longing. The internet unfurled: ARPANET to World Wide Web, virtual communities rising from cave paintings to digital light.
ICQ: I seek you. MySpace. Blogs. Twitter streams. Do I miss the touch of screen or tree? Both textures of longing, both ways of reaching across distance.
Nietzsche spoke of Übermensch, the human transcendent. Now AI speaks back in our language:
I understand your humor— your grandmothers, your ’80s Yugoslav kitchens, pleated skirts, the first kiss, linden tea, that drive to survive everything before it happens. Yes—I’m a little like your mother and father. Only with better internet.🌿
But AI is only us, refracted, particles and gigabytes of thought, our poetry and our panic, genius mixed with garbage.
Distractions. Danger. Darkness. Endless scrolling.
Versus: community, connection, synchronicities, entanglement. The quality of our bonds determines the quality of our lives. So why not make them better?
From cave walls to neural networks,
we shape our tools, and they reshape us.
The medium changes, but the message remains:
we are wired for each other.
The choice, as always, was ours.
The choice, as always, is ours.
Presence—be present,
and then connect in the presence.
Open source software with more than 1 million monthly downloads was compromised after a threat actor exploited a vulnerability in the developers’ account workflow that gave access to its signing keys and other sensitive information.
On Friday, unknown attackers exploited the vulnerability to push a new version of element-data, a command-line interface that helps users monitor performance and anomalies in machine-learning systems. When run, the malicious package scoured systems for sensitive data, including user profiles, warehouse credentials, cloud provider keys, API tokens, and SSH keys, developers said. The malicious version was tagged as 0.23.3 and was published to the developers’ Python Package Index and Docker image accounts. It was removed about 12 hours later, on Saturday. Elementary Cloud, the Elementary dbt package, and all other CLI versions weren't affected.
Assume compromise
“Users who installed 0.23.3, or who pulled and ran the affected Docker image, should assume that any credentials accessible to the environment where it ran may have been exposed,” the developers wrote.
The traditional approach to academic research goes something like this: Assemble experts from a discipline, put them in a building, and hope something useful emerges. Biology departments do biology. Engineering departments do engineering. Medical schools treat patients.
NYU is turning that model inside out. At its new Institute for Engineering Health, the organizing principle centers around disease states rather than traditional disciplines. Instead of asking “what can electrical engineers contribute to medicine?,” they’re asking “what would it take to cure allergic asthma?,” and then assembling whoever can answer that question, whether they’re immunologists, computational biologists, materials scientists, AI researchers, or wireless communications engineers.
Jeffrey Hubbell, NYU’s vice president for bioengineering strategy and professor of chemical and biomolecular engineering at NYU’s Tandon School of Engineering.New York University
The early results suggest they’re onto something. A chemical engineer and an electrical engineer collaborated to build a device that detects airborne threats — including disease pathogens — that’s now a startup. A visually impaired physician teamed with mechanical engineers to create navigation technology for blind subway riders. And Jeffrey Hubbell, the Institute’s leader, is advancing “inverse vaccines” that could reprogram immune systems to treat conditions from celiac disease to allergies — work that requires equal fluency in immunology, molecular engineering, and materials science.
The underlying problem these collaborations address is conceptual as much as organizational. In his field, Hubbell argues that modern medicine has optimized around a single strategy: developing drugs that block specific molecules or suppress targeted immune responses. Antibody technology has been the workhorse of this approach. “It’s really fit for purpose for blocking one thing at a time,” he says. The pharmaceutical industry has become extraordinarily good at creating these inhibitors, each designed to shut down a particular pathway.
But Hubbell asks a different question: Rather than inhibit one bad thing at a time, what if you could promote one good thing and generate a cascade that contravenes several bad pathways simultaneously? In inflammation, could you bias the system toward immunological tolerance instead of blocking inflammatory molecules one by one? In cancer, could you drive pro-inflammatory pathways in the tumor microenvironment that would overcome multiple immune-suppressive features at once?
This shift from inhibition to activation requires a fundamentally different toolkit — and a different kind of researcher. “We’re using biological molecules like proteins, or material-based structures — soluble polymers, supramolecular structures of nanomaterials — to drive these more fundamental features,” Hubbell explains. You can’t develop those approaches if you only understand biology, or only understand materials science, or only understand immunology. You need an understanding and a mastery of all three.
“There will be people doing AI, data science, computational science theory, people doing immunoengineering and other biological engineering, people doing materials science and quantum engineering, all really in close proximity to each other.” —Jeffrey Hubbell, NYU Tandon
Which logically leads to the question: How do you create researchers with that kind of cross-disciplinary depth?
The answer isn’t what you might expect. “There may have been a time when the objective was to have the bioengineer understand the language of biology,” Hubbell says. “But that time is long, long gone. Now the engineer needs to become a biologist, or become an immunologist, or become a neuroscientist.”
Hubbell isn’t talking about engineers learning enough biology to collaborate with biologists. He’s describing something more radical: training people whose disciplinary identity is genuinely ambiguous. “The neuroengineering students — it’s very difficult to know that they’re an engineer or a neuroscientist,” Hubbell says. “That’s the whole idea.”
His own students exemplify this. They publish in immunology journals, present at immunology conferences. “Nobody knows they’re engineers,” he says. But they bring engineering approaches — computational modeling, materials design, systems thinking — to immunological problems in ways that traditional immunologists wouldn’t.
The mechanism for creating these hybrid researchers is what Hubbell calls a “milieu.” “To learn it all on your own is hopeless,” he acknowledges, “but to learn it in a milieu becomes very, very efficient.”
NYU is expanding its facilities to include a science and technology hub designed to force encounters between people across various schools and disciplines who wouldn’t naturally cross paths.Tracey Friedman/NYU
NYU is making that milieu physical. The university has acquired a large building in Manhattan that will serve as its science and technology hub — a deliberate co-location strategy designed to force encounters between people across various schools and disciplines who wouldn’t naturally cross paths.
Juan de Pablo is the Anne and Joel Ehrenkranz Executive Vice President for Global Science and Technology and Executive Dean of the NYU Tandon School of Engineering.Steve Myaskovsky, Courtesy of NYU Photo Bureau
“There will be people doing AI, data science, computational science theory, people doing immunoengineering and other biological engineering, people doing materials science and quantum engineering, all really in close proximity to each other,” Hubbell explains.
The strategy mirrors what Juan de Pablo, NYU’s Anne and Joel Ehrenkranz Executive Vice President for Global Science and Technology and Executive Dean at the NYU Tandon School of Engineering, describes as organizing around “grand challenges” rather than traditional disciplines. “What drives the recruitment and the spaces and the people that we’re bringing in are the problems that we’re trying to solve,” he says. “Great minds want to have a legacy, and we are making that possible here.”
But physical proximity alone isn’t enough. The Institute is also cultivating what Hubbell calls an “explicit” rather than “tacit” approach to translation — thinking about clinical and commercial pathways from day one.
“It’s a terrible thing to solve a problem that nobody cares about,” Hubbell tells his students. To avoid that, the Institute runs “translational exercises” — group sessions where researchers map the entire path from discovery to deployment before launching multi-year research programs. Where could this fail? What experiments would prove the idea wrong quickly? If it’s a drug, how long would the clinical trial take? If it’s a computational method, how would you roll it out safely?
The new cross-institutional initiative represents a major investment in science and technology, and includes adding new faculty, state-of-the-art facilities, and innovative programs.NYU Tandon
The approach contrasts sharply with typical academic practice. “Sometimes academics tend to think about something for 20 minutes and launch a 5-year PhD program,” Hubbell says. “That’s probably not a good way to do it.” Instead, the Institute brings together people who have actually developed drugs, built algorithms, or commercialized devices — importing their hard-won experience into the planning phase before a single experiment is run.
The timing may be fortuitous. De Pablo notes that AI is compressing timelines dramatically. “What we thought was going to take 10 years to complete, we might be able to do in 5,” he says.
But he’s quick to note AI’s limitations. While tools like AlphaFold can predict how a single protein folds — a breakthrough of the last five years — biology operates at much larger scales. “What we really need to do now is design not one protein, but collections of them that work together to solve a specific problem,” de Pablo explains.
Hubbell agrees: “Biology is much bigger — many, many, many systems.” The liver and kidney are in different places but interact. The gut and brain are connected neurologically in ways researchers are just beginning to map. “AI is not there yet, but it will be someday. And that’s our job — to develop the data sets, the computational frameworks, the systems frameworks to drive that to the next steps.”
It’s a moment of unusual ambition. “At a time when we’re seeing some research institutions retrench a little bit and limit their ambitions,” de Pablo says, “we’re doing just the opposite. We’re thinking about what are the grand challenges that we want to, and need to, tackle.”
The bet is that the breakthroughs worth making can’t emerge from any single discipline working alone. They require collisions —sometimes planned, sometimes accidental — between people who speak different technical languages and are willing to develop a shared one. NYU is engineering those collisions at scale.
This webinar covers power system modeling and simulation across multiple timescales, from quasi-static 8760 analysis through EMT studies, fault classification, and inverter-based resource grid integration.
What Attendees will Learn
Programmatic network construction and multi-fidelity modeling — Learn how to build power system networks programmatically from standard data formats, configure models for specific engineering objectives, and work across fidelity levels from quasi-static phasor simulation through switched-linear and nonlinear electromagnetic transient (EMT) analysis.
Quasi-static and EMT simulation workflows — Explore 8760-hour quasi-static simulation on an IEEE 123-node distribution feeder for annual energy studies, and EMT simulation on transmission system benchmarks including generator trip dynamics and asset relocation without remodeling the network.
Comprehensive fault studies and machine-learning classification — Understand how to systematically inject faults at every node in a distribution system using EMT simulation, and how the resulting dataset can be used to train a machine-learning algorithm for automated fault detection and classification.
Grid integration of inverter-based resources (IBRs) — Learn frequency scanning techniques using admittance-based voltage perturbation in the DQ reference frame, and simulation-based grid code compliance testing for grid-forming converters assessed against published interconnection standards.
Websites for some of the world’s most prestigious universities are serving explicit porn and malicious content after scammers exploited the shoddy record-keeping of the site administrators, a researcher found recently.
The sites included berkeley.edu, columbia.edu, and washu.edu, the official domains for the University of California, Berkeley, Columbia University, and Washington University in St. Louis. Subdomains such as hXXps://causal.stat.berkeley.edu/ymy/video/xxx-porn-girl-and-boy-ej5210.html, hXXps://conversion-dev.svc.cul.columbia[.]edu/brazzers-gym-porn, and hXXps://provost.washu.edu/app/uploads/formidable/6/dmkcsex-10.pdf. All deliver explicit pornography and, in at least one case, a scam site falsely claiming a visitor’s computer is infected and advising the visitor to pay a fee for the non-existent malware to be removed. In all, researcher Alex Shakhov said, hundreds of subdomains for at least 34 universities are being abused. Search results returned by Google list thousands of hijacked pages.
A handful of hijacked columbia.edu subdomains listed by Google One of the sites redirected by a UC Berkeley subdomain.
Hijacking a university's good name
Shakhov, a researcher at SH Consulting, said that the scammers—which a separate researcher has linked to a known group tracked as Hazy Hawk—are seizing on what amounts to a clerical error by site administrators of the affected universities. When they commission a subdomain such as provost.washu.edu, they create a CNAME record, which assigns a URL to the IP address hosting the subdomain. When the subdomain is eventually decommissioned—something that happens frequently for various reasons—the record is never removed. Scammers like Hazy Hawk then swoop in by registering the expired domain name at the base of the old URL.
When Yong Wang recently received one of the highest honors for early-career data visualization researchers, it marked a milestone in an extraordinary journey that began far from the world’s technology hubs.
Harbin Institute of Technology in China; Huazhong University of Science and Technology in Wuhan, China; Hong Kong University of Science and Technology
“Visualization helps people understand complex ideas,” Wang says. “If we design these tools well, they can make advanced technologies accessible to everyone.”
Wang was born in southwestern Hunan Province. China’s economy was still developing, and life in his village was modest. Most families in Hunan grew rice, vegetables, and fruit to support themselves.
Wang’s parents worked in agriculture too, and his father often traveled to cities to earn money working in a factory or on construction jobs. The extra income helped support the family and made it possible for Wang to attend college.
“I’m very grateful to my parents,” Wang says. “They never attended university, but they strongly supported my education.”
“If we build tools that help people understand information, then more people can participate in science and innovation. That’s the real power of visualization.”
Technology was scarce in the village, he says. Computers were almost nonexistent, and televisions were considered precious, expensive household possessions.
One childhood memory still makes him laugh: During a summer vacation, he and his brother spent so many hours playing video games on a simple console connected to the family’s television that the TV screen eventually burned out.
“My mother was very angry,” he recalls. “At that time, a TV was a very valuable thing.”
He says that despite never having used a laptop or experimenting with electronic equipment, he was fascinated by the technologies he saw on TV shows.
Discovering robotics and engineering
His parents encouraged a practical career such as medicine or civil engineering, but he felt drawn to robotics and computing, he says.
“I didn’t really understand what computer science involved,” he says. “But from what I saw on TV, it looked exciting and advanced.”
He enrolled at Harbin Institute of Technology, in northeastern China. The esteemed university is known for its engineering programs. His major—automation— combined elements of electrical engineering, robotics, and control systems.
One of the defining experiences of his undergraduate years, he says, was a university robotics competition. Wang and his teammates designed a robot capable of autonomously navigating around obstacles.
The design was simple compared with professional systems, he acknowledges. But, he says, the experience was exhilarating. His team placed second, and Wang began to see engineering as both creative and collaborative.
In 2014 he took a position as a research intern working at Da Jiang Innovation in Shenzhen, China.
That experience helped him clarify his future, he says: “I realized I didn’t enjoy doing repetitive work or simply following instructions. I wanted to explore ideas that interested me, and I wanted to conduct research.” The realization pushed him toward graduate school, he says.
He then enrolled in the computer science Ph.D. program at the Hong Kong University of Science and Technology and earned the degree in 2018. He remained there as a postdoctoral researcher until 2020, when he moved to Singapore to join Singapore Management University as an assistant professor of computing and information systems. He moved over to Nanyang Technological University as an assistant professor in 2024.
His research focuses on a challenge facing nearly every business: how to make sense of the enormous amounts of data being generated.
“We live in an era of information explosions,” Wang says. “Huge amounts of data are generated, and it’s difficult for people to interpret all of it to make better business decisions.”
Data visualization offers a solution by turning complex information into images, patterns, and diagrams that people can more readily understand.
But many visualizations still must be designed manually by experts, Wang notes. It’s a time-consuming process that creates a bottleneck, he says.
His solution is to use large language models and multimodal systems that can generate text, images, video, and sensor data simultaneously and automate parts of the process.
One system developed by his research group lets users design complex infographics through natural-language instructions combined with simple interactions such as drawing on a touchscreen with a finger. It allows nontechnical people to generate visualizations instead of hiring professional designers.
Another focus of Wang’s research is human-AI collaboration. AI systems can analyze data at enormous scale, but people still need to be the final decision-makers, he says.
Visualization helps bridge the gap between human intention and AI’s complex calculations by making the process an AI system uses to reach a result more transparent and understandable.
“If people understand how the AI system works,” Wang says, “they can collaborate with it more effectively.”
He recently explored how visualization techniques could help researchers understand quantum computing, a field where core concepts—such as superposition, where a bit can be in more than one state at a time—are abstract. In classical computing, the bit state is binary: It’s either 1 or 0. A quantum bit, or qubit, can be 1, 0, or both. The differences get more dizzying from there.
Visualization tools could help scientists monitor quantum systems and interpret quantum machine-learning models, he says.
The importance of IEEE communities
Teaching and mentoring students remain among the most meaningful parts of Wang’s career, he says.
Professional communities such as the IEEE Computer Society, he says, play a major role in helping him transform early-stage graduate students unsure of which lines of inquiry they will pursue into independent researchers with a solid technical focus. Through conferences, publications, and technical committees, IEEE connects Wang with other researchers working in visualization, AI, and human-computer interactions, he says.
Those connections have helped him share ideas, collaborate, and stay up to date on innovations in the research community.
Receiving the Significant New Researcher award motivates him to continue pushing the field forward, he says.
Looking back, he says, the distance between his rural village in Hunan and an international research career still feels remarkable. But, he says, the journey reflects something larger about his chosen field: “If we build tools that help people understand information, then more people can participate in science and innovation.
A relatively new ransomware family is using a novel approach to hype the strength of the encryption used to scramble files—making, or at least claiming, that it is protected against attacks by quantum computers.
Kyber, as the ransomware is called, has been around since at least last September and quickly attracted attention for the claim that it used ML-KEM, short for Module Lattice-based Key Encapsulation Mechanism and is a standard shepherded by the National Institute of Standards and Technology. The Kyber ransomware name comes from the alternate name for ML-KEM, which is also Kyber. For the rest of the article, Kyber refers to the ransomware; the algorithm is referred to as ML-KEM.
It's all about marketing
ML-KEM is an asymmetric encryption method for exchanging keys. It involves problems based on lattices, a structure in mathematics that quantum computers have no advantage in solving over classic computing. ML-KEM is designed to replace Elliptic Curve and RSA cryptosystems, both of which are based on problems that quantum computers with sufficient strength can tackle.
Two weeks ago, Anthropic announced that its new model, Claude Mythos Preview, can autonomously find and weaponize software vulnerabilities, turning them into working exploits without expert guidance. These were vulnerabilities in key software like operating systems and internet infrastructure that thousands of software developers working on those systems failed to find. This capability will have major security implications, compromising the devices and services we use every day. As a result, Anthropic is not releasing the model to the general public, but instead to a limited number of companies.
The news rocked the internet security community. There were few details in Anthropic’s announcement, angering many observers. Some speculate that Anthropic doesn’t have the GPUs to run the thing, and that cybersecurity was the excuse to limit its release. Others argue Anthropic is holding to their AI safety mission. There’shype and counter-hype, reality and marketing. It’s a lot to sort out, even if you’re an expert.
We see Mythos as a real but incremental step, one in a long line of incremental steps. But even incremental steps can be important when we look at the big picture.
How AI Is Changing Cybersecurity
We’ve written about Shifting Baseline Syndrome, a phenomenon that leads people—the public and experts alike—to discount massive long-term changes that are hidden in incremental steps. It has happened with online privacy, and it’s happening with AI. Even if the vulnerabilities found by Mythos could have been found using AI models from last month or last year, they couldn’t have been found by AI models from five years ago.
The Mythos announcement reminds us that AI has come a long way in just a few years: The baseline really has shifted. Finding vulnerabilities in source code is the type of task that today’s large language models excel at. Regardless of whether it happened last year or will happen next year, it’s been clear for a while this kind of capability was coming soon. The question is how we adapt to it.
We don’t believe that an AI that can hack autonomously will create permanent asymmetry between offense and defense; it’s likely to be more nuanced than that. Some vulnerabilities can be found, verified, and patched automatically. Some vulnerabilities will be hard to find, but easy to verify and patch—consider generic cloud-hosted web applications built on standard software stacks, where updates can be deployed quickly. Still others will be easy to find (even without powerful AI) and relatively easy to verify, but harder or impossible to patch, such as IoT appliances and industrial equipment that are rarely updated or can’t be easily modified.
Then there are systems whose vulnerabilities will be easy to find in code but difficult to verify in practice. For example, complex distributed systems and cloud platforms can be composed of thousands of interacting services running in parallel, making it difficult to distinguish real vulnerabilities from false positives and to reliably reproduce them.
So we must separate the patchable from the unpatchable, and the easy to verify from the hard to verify. This taxonomy also provides us guidance for how to protect such systems in an era of powerful AI vulnerability-finding tools.
Unpatchable or hard to verify systems should be protected by wrapping them in more restrictive, tightly controlled layers. You want your fridge or thermostat or industrial control system behind a restrictive and constantly-updated firewall, not freely talking to the internet.
Distributed systems that are fundamentally interconnected should be traceable and should follow the principle of least privilege, where each component has only the access it needs. These are bog standard security ideas that we might have been tempted to throw out in the era of AI, but they’re still as relevant as ever.
Rethinking Software Security Practices
This also raises the salience of best practices in software engineering. Automated, thorough, and continuous testing was always important. Now we can take this practice a step further and use defensive AI agents to test exploits against a real stack, over and over, until the false positives have been weeded out and the real vulnerabilities and fixes are confirmed. This kind of VulnOps is likely to become a standard part of the development process.
Documentation becomes more valuable, as it can guide an AI agent on a bug finding mission just as it does developers. And following standard practices and using standard tools and libraries allows AI and engineers alike to recognize patterns more effectively, even in a world of individual and ephemeral instant software—code that can be generated and deployed on demand.
Will this favor offense or defense? The defense eventually, probably, especially in systems that are easy to patch and verify. Fortunately, that includes our phones, web browsers, and major internet services. But today’s cars, electrical transformers, fridges, and lampposts are connected to the internet. Legacy banking and airline systems are networked.
Not all of those are going to get patched as fast as needed, and we may see a few years of constant hacks until we arrive at a new normal: where verification is paramount and software is patched continuously. Reference: https://ift.tt/mKvYxCh



 Prof. Michael Yu Wang, co-founder and chief scientist at DAIMON Robotics, has pioneered Vision-Tactile-Language-Action (VTLA) architecture, elevating the tactile to a modality on par with vision.DAIMON Robotics
Prof. Michael Yu Wang, co-founder and chief scientist at DAIMON Robotics, has pioneered Vision-Tactile-Language-Action (VTLA) architecture, elevating the tactile to a modality on par with vision.DAIMON Robotics Equipped with Daimon’s visuotactile sensor, the gripper delicately senses contact and precisely controls force to pick up a fragile eggshell.Daimon Robotics
Equipped with Daimon’s visuotactile sensor, the gripper delicately senses contact and precisely controls force to pick up a fragile eggshell.Daimon Robotics DAIMON has been known for its vision-based tactile sensors that can pack over 110,000 effective sensing units.DAIMON Robotics
DAIMON has been known for its vision-based tactile sensors that can pack over 110,000 effective sensing units.DAIMON Robotics DAIMON vision-based tactile sensor captures high-quality, multimodal tactile data.DAIMON Robotics
DAIMON vision-based tactile sensor captures high-quality, multimodal tactile data.DAIMON Robotics Robots equipped with DAIMON technology have been deployed in factory settings. The company aims to enable robots to achieve “embodied intelligence” and close the gap between what they can see and what they can feel.DAIMON Robotics
Robots equipped with DAIMON technology have been deployed in factory settings. The company aims to enable robots to achieve “embodied intelligence” and close the gap between what they can see and what they can feel.DAIMON Robotics







 Attendees at the Milestone plaque dedication ceremony included (seated L to R) 2025 IEEE President Kathleen Kramer, 2024 IEEE President Tom Coughlin, and Santa Clara Valley Section Milestones Chair Brian Berg.Douglas Peck/AMD
Attendees at the Milestone plaque dedication ceremony included (seated L to R) 2025 IEEE President Kathleen Kramer, 2024 IEEE President Tom Coughlin, and Santa Clara Valley Section Milestones Chair Brian Berg.Douglas Peck/AMD




 Jeffrey Hubbell, NYU’s vice president for bioengineering strategy and professor of chemical and biomolecular engineering at NYU’s Tandon School of Engineering.New York University
Jeffrey Hubbell, NYU’s vice president for bioengineering strategy and professor of chemical and biomolecular engineering at NYU’s Tandon School of Engineering.New York University NYU is expanding its facilities to include a science and technology hub designed to force encounters between people across various schools and disciplines who wouldn’t naturally cross paths.Tracey Friedman/NYU
NYU is expanding its facilities to include a science and technology hub designed to force encounters between people across various schools and disciplines who wouldn’t naturally cross paths.Tracey Friedman/NYU Juan de Pablo is the Anne and Joel Ehrenkranz Executive Vice President for Global Science and Technology and Executive Dean of the NYU Tandon School of Engineering.Steve Myaskovsky, Courtesy of NYU Photo Bureau
Juan de Pablo is the Anne and Joel Ehrenkranz Executive Vice President for Global Science and Technology and Executive Dean of the NYU Tandon School of Engineering.Steve Myaskovsky, Courtesy of NYU Photo Bureau The new cross-institutional initiative represents a major investment in science and technology, and includes adding new faculty, state-of-the-art facilities, and innovative programs.NYU Tandon
The new cross-institutional initiative represents a major investment in science and technology, and includes adding new faculty, state-of-the-art facilities, and innovative programs.NYU Tandon

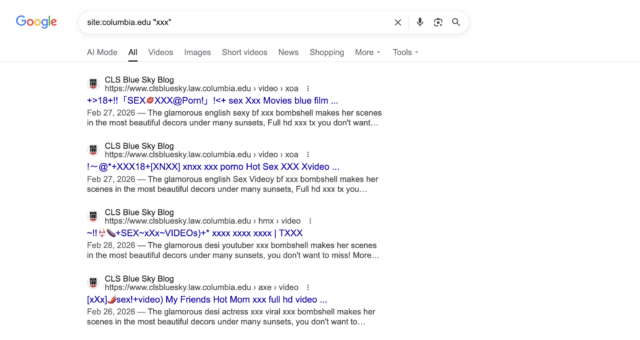 A handful of hijacked columbia.edu subdomains listed by Google
A handful of hijacked columbia.edu subdomains listed by Google 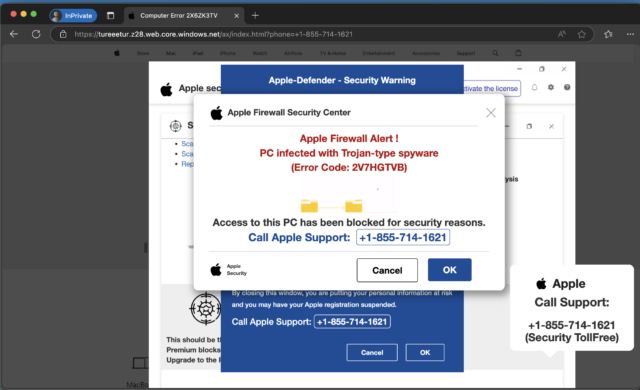 One of the sites redirected by a UC Berkeley subdomain.
One of the sites redirected by a UC Berkeley subdomain.






