

How much thought do you give to where you keep your bits? Every day we produce more data, including emails, texts, photos, and social media posts. Though much of this content is forgettable, every day we implicitly decide not to get rid of that data. We keep it somewhere, be it in on a phone, on a computer’s hard drive, or in the cloud, where it is eventually archived, in most cases on magnetic tape. Consider further the many varied devices and sensors now streaming data onto the Web, and the cars, airplanes, and other vehicles that store trip data for later use. All those billions of things on the Internet of Things produce data, and all that information also needs to be stored somewhere.
Data is piling up exponentially, and the rate of information production is increasing faster than the storage density of tape, which will only be able to keep up with the deluge of data for a few more years. The research firm Gartner predicts that by 2030, the shortfall in enterprise storage capacity alone could amount to nearly two-thirds of demand, or about 20 million petabytes. If we continue down our current path, in coming decades we would need not only exponentially more magnetic tape, disk drives, and flash memory, but exponentially more factories to produce these storage media, and exponentially more data centers and warehouses to store them. Even if this is technically feasible, it’s economically implausible.
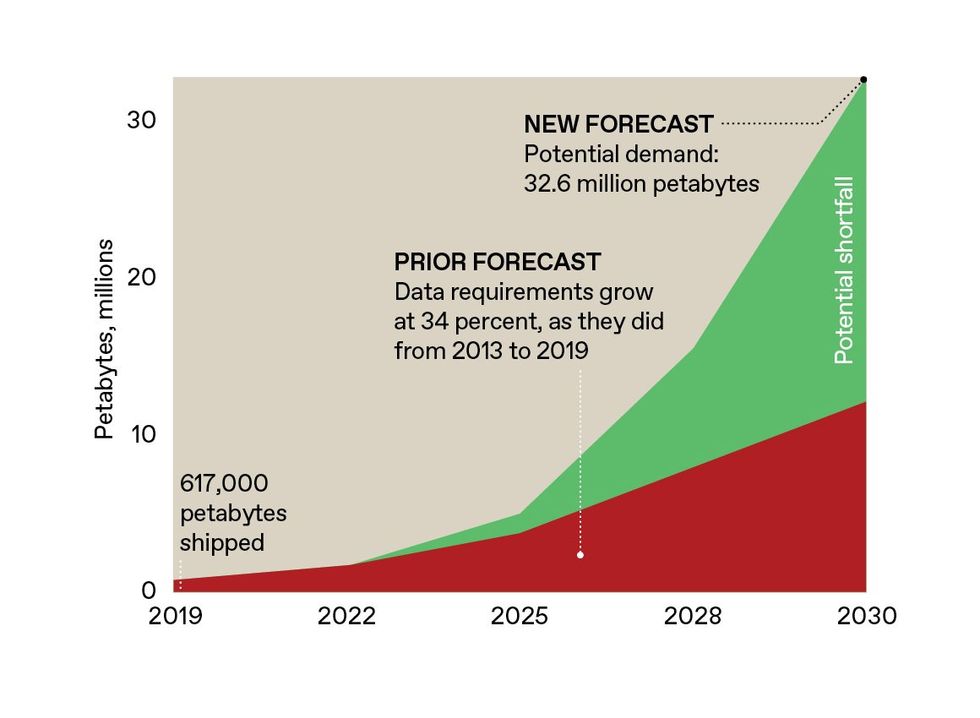 Prior projections for data storage requirements estimated a global need for about 12 million petabytes of capacity by 2030. The research firm Gartner recently issued new projections, raising that estimate by 20 million petabytes. The world is not on track to produce enough of today’s storage technologies to fill that gap.SOURCE: GARTNER
Prior projections for data storage requirements estimated a global need for about 12 million petabytes of capacity by 2030. The research firm Gartner recently issued new projections, raising that estimate by 20 million petabytes. The world is not on track to produce enough of today’s storage technologies to fill that gap.SOURCE: GARTNER
Fortunately, we have access to an information storage technology that is cheap, readily available, and stable at room temperature for millennia: DNA, the material of genes. In a few years your hard drive may be full of such squishy stuff.
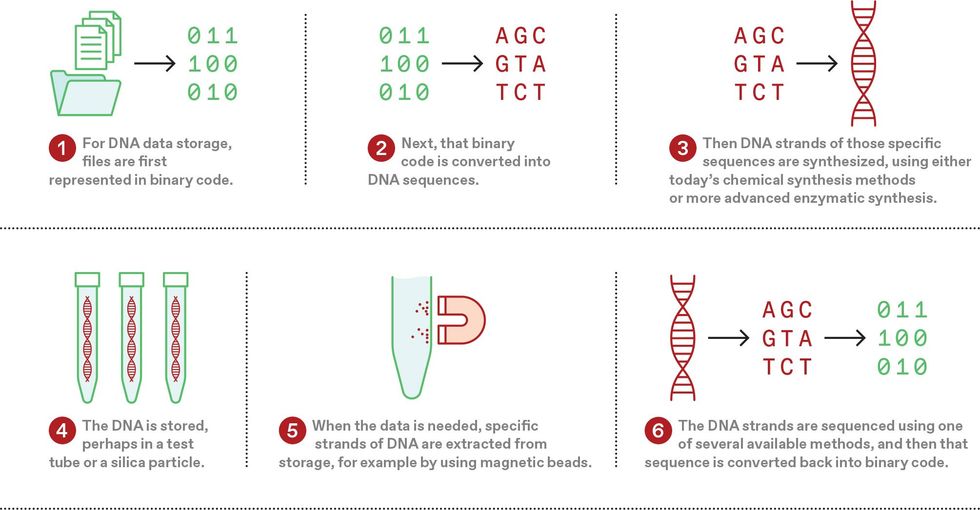
Storing information in DNA is not a complicated concept. Decades ago, humans learned to sequence and synthesize DNA—that is, to read and write it. Each position in a single strand of DNA consists of one of four nucleic acids, known as bases and represented as A, T, G, and C. In principle, each position in the DNA strand could be used to store two bits (A could represent 00, T could be 01, and so on), but in practice, information is generally stored at an effective one bit—a 0 or a 1—per base.
Moreover, DNA exceeds by many times the storage density of magnetic tape or solid-state media. It has been calculated that all the information on the Internet—which one estimate puts at about 120 zettabytes—could be stored in a volume of DNA about the size of a sugar cube, or approximately a cubic centimeter. Achieving that density is theoretically possible, but we could get by with a much lower storage density. An effective storage density of “one Internet per 1,000 cubic meters” would still result in something considerably smaller than a single data center housing tape today.
 In 2018, researchers built this first prototype of a machine that could write, store, and read data with DNA.MICROSOFT RESEARCH
In 2018, researchers built this first prototype of a machine that could write, store, and read data with DNA.MICROSOFT RESEARCH
Most examples of DNA data storage to date rely on chemically synthesizing short stretches of DNA, up to 200 or so bases. Standard chemical synthesis methods are adequate for demonstration projects, and perhaps early commercial efforts, that store modest amounts of music, images, text, and video, up to perhaps hundreds of gigabytes. However, as the technology matures, we will need to switch from chemical synthesis to a much more elegant, scalable, and sustainable solution: a semiconductor chip that uses enzymes to write these sequences.
After the data has been written into the DNA, the molecule must be kept safe somewhere. Published examples include drying small spots of DNA on glass or paper, encasing the DNA in sugar or silica particles, or just putting it in a test tube. Reading can be accomplished with any number of commercial sequencing technologies.
Organizations around the world are already taking the first steps toward building a DNA drive that can both write and read DNA data. I’ve participated in this effort via a collaboration between Microsoft and the Molecular Information Systems Lab of the Paul G. Allen School of Computer Science and Engineering at the University of Washington. We’ve made considerable progress already, and we can see the way forward.
How bad is the data storage problem?
First, let’s look at the current state of storage. As mentioned, magnetic tape storage has a scaling problem. Making matters worse, tape degrades quickly compared to the time scale on which we want to store information. To last longer than a decade, tape must be carefully stored at cool temperatures and low humidity, which typically means the continuous use of energy for air conditioning. And even when stored carefully, tape needs to be replaced periodically, so we need more tape not just for all the new data but to replace the tape storing the old data.
To be sure, the storage density of magnetic tape has been increasing for decades, a trend that will help keep our heads above the data flood for a while longer. But current practices are building fragility into the storage ecosystem. Backward compatibility is often guaranteed for only a generation or two of the hardware used to read that media, which could be just a few years, requiring the active maintenance of aging hardware or ongoing data migration. So all the data we have already stored digitally is at risk of being lost to technological obsolescence.
How DNA data storage works
The discussion thus far has assumed that we’ll want to keep all the data we produce, and that we’ll pay to do so. We should entertain the counterhypothesis: that we will instead engage in systematic forgetting on a global scale. This voluntary amnesia might be accomplished by not collecting as much data about the world or by not saving all the data we collect, perhaps only keeping derivative calculations and conclusions. Or maybe not every person or organization will have the same access to storage. If it becomes a limited resource, data storage could become a strategic technology that enables a company, or a country, to capture and process all the data it desires, while competitors suffer a storage deficit. But as yet, there’s no sign that producers of data are willing to lose any of it.
If we are to avoid either accidental or intentional forgetting, we need to come up with a fundamentally different solution for storing data, one with the potential for exponential improvements far beyond those expected for tape. DNA is by far the most sophisticated, stable, and dense information-storage technology humans have ever come across or invented. Readable genomic DNA has been recovered after having been frozen in the tundra for 2 million years. DNA is an intrinsic part of life on this planet. As best we can tell, nucleic acid–based genetic information storage has persisted on Earth for at least 3 billion years, giving it an unassailable advantage as a backward- and forward-compatible data storage medium.
What are the advantages of DNA data storage?
To date, humans have learned to sequence and synthesize short pieces of single-stranded DNA (ssDNA). However, in naturally occurring genomes, DNA is usually in the form of long, double-stranded DNA (dsDNA). This dsDNA is composed of two complementary sequences bound into a structure that resembles a twisting ladder, where sugar backbones form the side rails, and the paired bases—A with T, and G with C—form the steps of the ladder. Due to this structure, dsDNA is generally more robust than ssDNA.
Reading and writing DNA are both noisy molecular processes. To enable resiliency in the presence of this noise, digital information is encoded using an algorithm that introduces redundancy and distributes information across many bases. Current algorithms encode information at a physical density of 1 bit per 60 atoms (a pair of bases and the sugar backbones to which they’re attached).
 Edmon de Haro
Edmon de Haro
Synthesizing and sequencing DNA has become critical to the global economy, to human health, and to understanding how organisms and ecosystems are changing around us. And we’re likely to only get better at it over time. Indeed, both the cost and the per-instrument throughput of writing and reading DNA have been improving exponentially for decades, roughly keeping up with Moore’s Law.
In biology labs around the world, it’s now common practice to order chemically synthesized ssDNA from a commercial provider; these molecules are delivered in lengths of up to several hundred bases. It is also common to sequence DNA molecules that are up to thousands of bases in length. In other words, we already convert digital information to and from DNA, but generally using only sequences that make sense in terms of biology.
For DNA data storage, though, we will have to write arbitrary sequences that are much longer, probably thousands to tens of thousands of bases. We’ll do that by adapting the naturally occurring biological process and fusing it with semiconductor technology to create high-density input and output devices.
There is global interest in creating a DNA drive. The members of the DNA Data Storage Alliance, founded in 2020, come from universities, companies of all sizes, and government labs from around the world. Funding agencies in the United States, Europe, and Asia are investing in the technology stack required to field commercially relevant devices. Potential customers as diverse as film studios, the U.S. National Archives, and Boeing have expressed interest in long-term data storage in DNA.
Archival storage might be the first market to emerge, given that it involves writing once with only infrequent reading, and yet also demands stability over many decades, if not centuries. Storing information in DNA for that time span is easily achievable. The challenging part is learning how to get the information into, and back out of, the molecule in an economically viable way.
What are the R&D challenges of DNA data storage?
The first soup-to-nuts automated prototype capable of writing, storing, and reading DNA was built by my Microsoft and University of Washington colleagues in 2018. The prototype integrated standard plumbing and chemistry to write the DNA, with a sequencer from the company Oxford Nanopore Technologies to read the DNA. This single-channel device, which occupied a tabletop, had a throughput of 5 bytes over approximately 21 hours, with all but 40 minutes of that time consumed in writing “HELLO” into the DNA. It was a start.
For a DNA drive to compete with today’s archival tape drives, it must be able to write about 2 gigabits per second, which at demonstrated DNA data storage densities is about 2 billion bases per second. To put that in context, I estimate that the total global market for synthetic DNA today is no more than about 10 terabases per year, which is the equivalent of about 300,000 bases per second over a year. The entire DNA synthesis industry would need to grow by approximately 4 orders of magnitude just to compete with a single tape drive. Keeping up with the total global demand for storage would require another 8 orders of magnitude of improvement by 2030.
Exponential growth in silicon-based technology is how we wound up producing so much data. Similar exponential growth will be fundamental in the transition to DNA storage.
But humans have done this kind of scaling up before. Exponential growth in silicon-based technology is how we wound up producing so much data. Similar exponential growth will be fundamental in the transition to DNA storage.
My work with colleagues at the University of Washington and Microsoft has yielded many promising results. This collaboration has made progress on error-tolerant encoding of DNA, writing information into DNA sequences, stably storing that DNA, and recovering the information by reading the DNA. The team has also explored the economic, environmental, and architectural advantages of DNA data storage compared to alternatives.
One of our goals was to build a semiconductor chip to enable high-density, high-throughput DNA synthesis. That chip, which we completed in 2021, demonstrated that it is possible to digitally control electrochemical processes in millions of 650-nanometer-diameter wells. While the chip itself was a technological step forward, the chemical synthesis we used on that chip had a few drawbacks, despite being the industry standard. The main problem is that it employs a volatile, corrosive, and toxic organic solvent (acetonitrile), which no engineer wants anywhere near the electronics of a working data center.
Moreover, based on a sustainability analysis of a theoretical DNA data center performed my colleagues at Microsoft, I conclude that the volume of acetonitrile required for just one large data center, never mind many large data centers, would become logistically and economically prohibitive. To be sure, each data center could be equipped with a recycling facility to reuse the solvent, but that would be costly.
Fortunately, there is a different emerging technology for constructing DNA that does not require such solvents, but instead uses a benign salt solution. Companies like DNA Script and Molecular Assemblies are commercializing automated systems that use enzymes to synthesize DNA. These techniques are replacing traditional chemical DNA synthesis for some applications in the biotechnology industry. The current generation of systems use either simple plumbing or light to control synthesis reactions. But it’s difficult to envision how they can be scaled to achieve a high enough throughput to enable a DNA data-storage device operating at even a fraction of 2 gigabases per second.
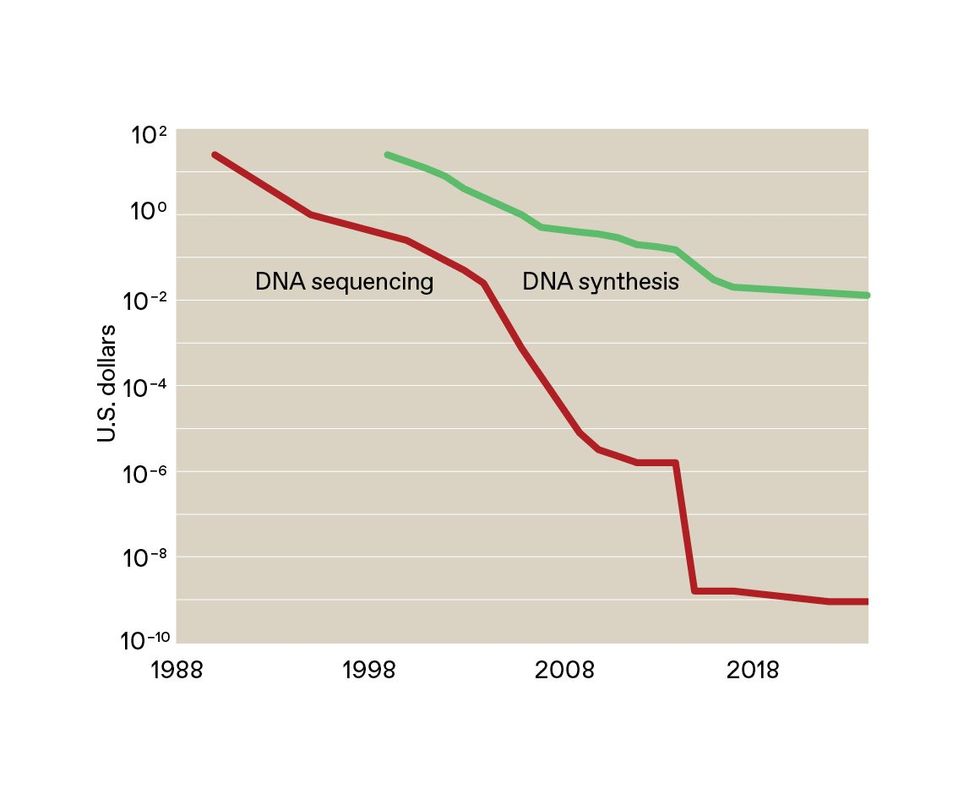 The price for sequencing DNA has plummeted from $25 per base in 1990 to less than a millionth of a cent in 2024. The cost of synthesizing long pieces of double-stranded DNA is also declining, but synthesis needs to become much cheaper for DNA data storage to really take off.SOURCE: ROB CARLSON
The price for sequencing DNA has plummeted from $25 per base in 1990 to less than a millionth of a cent in 2024. The cost of synthesizing long pieces of double-stranded DNA is also declining, but synthesis needs to become much cheaper for DNA data storage to really take off.SOURCE: ROB CARLSON
Still, the enzymes inside these systems are important pieces of the DNA drive puzzle. Like DNA data storage, the idea of using enzymes to write DNA is not new, but commercial enzymatic synthesis became feasible only in the last couple of years. Most such processes use an enzyme called terminal deoxynucleotidyl transferase, or TdT. Whereas most enzymes that operate on DNA use one strand as a template to fill in the other strand, TdT can add arbitrary bases to single-stranded DNA.
Naturally occurring TdT is not a great enzyme for synthesis, because it incorporates the four bases with four different efficiencies, and it’s hard to control. Efforts over the past decade have focused on modifying the TdT and building it into a system in which the enzyme can be better controlled.
Notably, those modifications to TdT were made possible by prior decades of improvement in reading and writing DNA, and the new modified enzymes are now contributing to further improvements in writing, and thus modifying, genes and genomes. This phenomenon is the same type of feedback that drove decades of exponential improvement in the semiconductor industry, in which companies used more capable silicon chips to design the next generation of silicon chips. Because that feedback continues apace in both arenas, it won’t be long before we can combine the two technologies into one functional device: a semiconductor chip that converts digital signals into chemical states (for example, changes in pH), and an enzymatic system that responds to those chemical states by adding specific, individual bases to build a strand of synthetic DNA.
The University of Washington and Microsoft team, collaborating with the enzymatic synthesis company Ansa Biotechnologies, recently took the first step toward this device. Using our high-density chip, we successfully demonstrated electrochemical control of single-base enzymatic additions. The project is now paused while the team evaluates possible next steps.Nevertheless, even if this effort is not resumed, someone will make the technology work. The path is relatively clear; building a commercially relevant DNA drive is simply a matter of time and money.
Looking beyond DNA data storage
Eventually, the technology for DNA storage will completely alter the economics of reading and writing all kinds of genetic information. Even if the performance bar is set far below that of a tape drive, any commercial operation based on reading and writing data into DNA will have a throughput many times that of today’s DNA synthesis industry, with a vanishingly small cost per base.
At the same time, advances in DNA synthesis for DNA storage will increase access to DNA for other uses, notably in the biotechnology industry, and will thereby expand capabilities to reprogram life. Somewhere down the road, when a DNA drive achieves a throughput of 2 gigabases per second (or 120 gigabases per minute), this box could synthesize the equivalent of about 20 complete human genomes per minute. And when humans combine our improving knowledge of how to construct a genome with access to effectively free synthetic DNA, we will enter a very different world.
The conversations we have today about biosecurity, who has access to DNA synthesis, and whether this technology can be controlled are barely scratching the surface of what is to come. We’ll be able to design microbes to produce chemicals and drugs, as well as plants that can fend off pests or sequester minerals from the environment, such as arsenic, carbon, or gold. At 2 gigabases per second, constructing biological countermeasures against novel pathogens will take a matter of minutes. But so too will constructing the genomes of novel pathogens. Indeed, this flow of information back and forth between the digital and the biological will mean that every security concern from the world of IT will also be introduced into the world of biology. We will have to be vigilant about these possibilities.
We are just beginning to learn how to build and program systems that integrate digital logic and biochemistry. The future will be built not from DNA as we find it, but from DNA as we will write it.
Reference: https://ift.tt/1waCd4Y



No comments:
Post a Comment