

Large language models like Llama2 and ChatGPT are where much of the action is in AI. But how well do today’s datacenter-class computers execute them? Pretty well, according to the latest set of benchmark results for machine learning, with the best able to summarize more than 100 articles in a second. MLPerf’s twice-a-year data delivery was released on 11 September and included, for the first time, a test of a large-language model (LLM), GPT-J. Fifteen computer companies submitted performance results in this first LLM trial, adding to the more than 13,000 other results submitted by a total of 26 companies. In one of the highlights of the datacenter category, Nvidia revealed the first benchmark results for its Grace Hopper—an H100 GPU linked to the company’s new Grace CPU in the same package as if they were a single “superchip.”
Sometimes called “the Olympics of machine learning,” MLPerf consists of seven benchmark tests: image recognition, medical-imaging segmentation, object detection, speech recognition, natural-language processing, a new recommender system, and now a LLM. This set of benchmarks tested how well an already-trained neural network executed on different computer systems, a process called inferencing.
[For more details on how MLPerf works in general, go here.]
The LLM, called GPT-J and released in 2021, is on the small side for such AIs. It’s made up of some 6 billion parameters compared to GPT-3’s 175 billion. But going small was on purpose, according to MLCommons executive director David Kanter, because the organization wanted the benchmark to be achievable by a big swath of the computing industry. It’s also in line with a trend toward more compact but still capable neural networks.
This was version 3.1 of the inferencing contest, and as in previous iterations, Nvidia dominated both in the number of machines using its chips and in performance. However, Intel’s Habana Gaudi2 continued to nip at the Nvidia H100’s heels and Qualcomm’s Cloud AI 100 chips made a strong showing in benchmarks focused on power consumption.
Nvidia Still on Top
This set of benchmarks saw the arrival of the Grace Hopper superchip, an Arm-based 72-core CPU fused to an H100 through Nvidia’s proprietary C2C link. Most other H100 systems rely on Intel Xeon or AMD Epyc CPUs housed in a separate package.
The nearest comparable system to the Grace Hopper was an Nvidia DGX H100 computer that combined two Intel Xeon CPUs with an H100 GPU. The Grace Hopper machine beat that in every category by 2 to 14 percent, depending on the benchmark. The biggest difference was achieved in the recommender system test and the smallest in the LLM test.
Dave Salvatore, director of AI inference, benchmarking, and cloud at Nvidia, attributed much of the Grace Hopper advantage to memory access. Through the proprietary C2C link that binds the Grace chip to the Hopper chip, the GPU can directly access 480 GB of CPU memory and there is an additional 16 GB of high-bandwidth memory attached to the Grace chip itself. (The next generation of Grace Hopper will add even more memory capacity, climbing to 140 GB from its 96 GB total today, Salvatore says.) The combined chip can also steer extra power to the GPU when the CPU is less busy, allowing the GPU to ramp up its performance.
Besides Grace Hopper’s arrival, Nvidia had its usual fine showing, as you can see in the charts below of all the inference performance results for datacenter-class computers.
MLPerf Datacenter Inference v3.1 Results
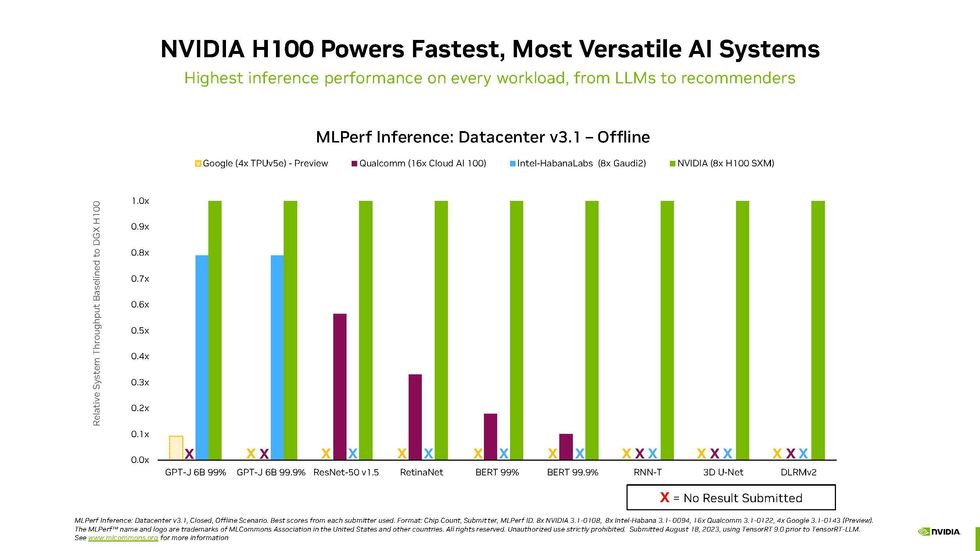
Things could get even better for the GPU giant. Nvidia announced a new software library that effectively doubled the H100’s performance on GPT-J. Called TensorRT-LLM, it wasn’t ready in time for MLPerf v3.1 tests, which were submitted in early August. The key innovation is something called inflight batching, says Salvatore. The work involved in executing an LLM can vary a lot. For example, the same neural network can be asked to turn a 20-page article into a one-page essay or a summarize a 1 page article in 100 words. TensorRT-LLM basically keeps these queries from stalling each other, so small queries can get done while big jobs are in process, too.

Intel Closes In
Intel’s Habana Gaudi2 accelerator has been stalking the H100 in previous rounds of benchmarks. This time Intel only trialed a single 2-CPU, 8-accelerator computer and only on the LLM benchmark. That system trailed Nvidia’s fastest machine by between 8 and 22 percent at the task.
“In inferencing we are at almost parity with H100,” says Jordan Plawner, senior director of AI products at Intel. Customers, he says, are coming to see the Habana chips as “the only viable alternative to the H100,” which is in enormously high demand.
He also noted that Gaudi 2 is a generation behind the H100 in terms of chip manufacturing technology. The next generation will use the same chip technology as H100, he says.
Intel has also historically used MLPerf to show how much can be done using CPUs alone, albeit CPUs that now come with a dedicated matrix computation unit to help with neural networks. This round was no different. Six systems of two Intel Xeon CPUs each were tested on the LLM benchmark. While they didn’t perform anywhere near GPU standards—the Grace Hopper system was often ten times or more faster than any of them—they could still spit out a summary every second or so.
Datacenter Efficiency Results
Only Qualcomm and Nvidia chips were measured for this category. Qualcomm has previously emphasized its accelerators power efficiency, but Nvidia H100 machines competed well, too.
Reference: https://ift.tt/mjeHALz




No comments:
Post a Comment