Enlarge/ Thirst for the ".ai" domain has put Anguilla on the global technology map. (credit: Getty Images)
Anguilla, a tiny British island territory in the Caribbean, may bring in up to $30 million in revenue this year thanks to its ".ai" domain name, reports Bloomberg in a piece published Thursday. Over the past year, skyrocketing interest in AI has made the country's ".ai" top-level domain particularly attractive to tech companies. The revenue is a boon for Anguilla's economy, which primarily relies on tourism and has been impacted by the pandemic.
$30 million from domains may not sound like a lot compared to the billions thrown around in AI these days, but with a total land area of 35 square miles and a population of 15,753, Anguilla isn't complaining. Registrars like GoDaddy must pay Anguilla a fixed price—$140 for a two-year registration—and the prices are rising due to demand.
Bloomberg says that Anguilla brought in a mere $7.4 million from .ai domain registrations in 2021, but all that changed with the release of OpenAI's ChatGPT last year. Its release spawned a huge wave of AI hype, fear, and investment. Vince Cate, who has managed the ".ai" domain for Anguilla for decades, told Bloomberg that .ai registrations have effectively doubled in the past year. "Since November 30, things are very different here," he said.
Enlarge/ An Alameda County couple watches as investigators prepare to retrieve the body of Nina Reiser in the Oakland hills in July 2008. Hans Reiser, creator of the ReiserFS file system, provided the location after his 2008 murder conviction. (credit: Carlos Avila Gonzalez/The San Francisco Chronicle via Getty Images)
When Apple was about to introduce Time Machine in Mac OS X Leopard, John Siracusa wrote in the summer of 2006 about how a new file system should be coming to Macs (which it did, 11 years later). The Mac, Siracusa wrote, needed something that could efficiently handle lots of tiny files, volume management with pooled storage, checksum-based data integrity, and snapshots. It needed something like ZFS or, perhaps, ReiserFS, file systems “notable for their willingness to reconsider past assumptions about file system design.”
Two months later, the name Reiser would lose most of its prestige and pick up a tragic association it would never shake. Police arrested the file system’s namesake, Hans Reiser, and charged him with murder in connection with the disappearance of his estranged wife.
Reiser’s work on Linux file systems was essentially sentenced to obscurity from that point on. Now that designation has been made official, as the file system that was once the default on systems like SUSE Linux has been changed from “Supported” to “Obsolete” in the latest Linux 6.6 kernel merge process (as reported by Phoronix). While a former employee of Reiser’s company, Namesys, continues out-of-source work on later versions of ReiserFS, it is likely to disappear from the kernel entirely in a matter of years, likely 2025.
In July, OpenAI announced a new research program on “superalignment.” The program has the ambitious goal of solving the hardest problem in the field known as AI alignment by 2027, an effort to which OpenAI is dedicating 20 percent of its total computing power.
What is the AI alignment problem? It’s the idea that AI systems’ goals may not align with those of humans, a problem that would be heightened if superintelligent AI systems are developed. Here’s where people start talking about extinction risks to humanity. OpenAI’s superalignment project is focused on that bigger problem of aligning artificial superintelligence systems. As OpenAI put it in its introductory blog post: “We need scientific and technical breakthroughs to steer and control AI systems much smarter than us.”
The effort is co-led by OpenAI’s head of alignment research, Jan Leike, and Ilya Sutskever, OpenAI’s cofounder and chief scientist. Leike spoke to IEEE Spectrum about the effort, which has the subgoal of building an aligned AI research tool--to help solve the alignment problem.
IEEE Spectrum: Let’s start with your definition of alignment. What is an aligned model?
Jan Leike, head of OpenAI’s alignment research is spearheading the company’s effort to get ahead of artificial superintelligence before it’s ever created.OpenAI
Jan Leike: What we want to do with alignment is we want to figure out how to make models that follow human intent and do what humans want—in particular, in situations where humans might not exactly know what they want. I think this is a pretty good working definition because you can say, “What does it mean for, let’s say, a personal dialog assistant to be aligned? Well, it has to be helpful. It shouldn’t lie to me. It shouldn’t say stuff that I don’t want it to say.”
Leike: I wouldn’t say ChatGPT is aligned. I think alignment is not binary, like something is aligned or not. I think of it as a spectrum between systems that are very misaligned and systems that are fully aligned. And [with ChatGPT] we are somewhere in the middle where it’s clearly helpful a lot of the time. But it’s also still misaligned in some important ways. You can jailbreak it, and it hallucinates. And sometimes it’s biased in ways that we don’t like. And so on and so on. There’s still a lot to do.
“It’s still early days. And especially for the really big models, it’s really hard to do anything that is nontrivial.”
—Jan Leike, OpenAI
Let’s talk about levels of misalignment. Like you said, ChatGPT can hallucinate and give biased responses. So that’s one level of misalignment. Another level is something that tells you how to make a bioweapon. And then, the third level is a super-intelligent AI that decides to wipe out humanity. Where in that spectrum of harms can your team really make an impact?
Leike: Hopefully, on all of them. The new superalignment team is not focused on alignment problems that we have today as much. There’s a lot of great work happening in other parts of OpenAI on hallucinations and improving jailbreaking. What our team is most focused on is the last one. How do we prevent future systems that are smart enough to disempower humanity from doing so? Or how do we align them sufficiently that they can help us do automated alignment research, so we can figure out how to solve all of these other alignment problems.
I heard you say in a podcast interview that GPT-4 isn’t really capable of helping with alignment, and you know because you tried. Can you tell me more about that?
Leike: Maybe I should have made a more nuanced statement. We’ve tried to use it in our research workflow. And it’s not like it never helps, but on average, it doesn’t help enough to warrant using it for our research. If you wanted to use it to help you write a project proposal for a new alignment project, the model didn’t understand alignment well enough to help us. And part of it is that there isn’t that much pre-training data for alignment. Sometimes it would have a good idea, but most of the time, it just wouldn’t say anything useful. We’ll keep trying.
Next one, maybe.
Leike: We’ll try again with the next one. It will probably work better. I don’t know if it will work well enough yet.
Let’s talk about some of the strategies that you’re excited about. Can you tell me about scalable human oversight?
Leike: Basically, if you look at how systems are being aligned today, which is using reinforcement learning from human feedback (RLHF)—on a high level, the way it works is you have the system do a bunch of things, say write a bunch of different responses to whatever prompt the user puts into chat GPT, and then you ask a human which one is best. But this assumes that the human knows exactly how the task works and what the intent was and what a good answer looks like. And that’s true for the most part today, but as systems get more capable, they also are able to do harder tasks. And harder tasks will be more difficult to evaluate. So for example, in the future if you have GPT-5 or 6 and you ask it to write a code base, there’s just no way we’ll find all the problems with the code base. It’s just something humans are generally bad at. So if you just use RLHF, you wouldn’t really train the system to write a bug-free code base. You might just train it to write code bases that don’t have bugs that humans easily find, which is not the thing we actually want.
“There are some important things you have to think about when you’re doing this, right? You don’t want to accidentally create the thing that you’ve been trying to prevent the whole time.”
—Jan Leike, OpenAI
The idea behind scalable oversight is to figure out how to use AI to assist human evaluation. And if you can figure out how to do that well, then human evaluation or assisted human evaluation will get better as the models get more capable, right? For example, we could train a model to write critiques of the work product. If you have a critique model that points out bugs in the code, even if you wouldn’t have found a bug, you can much more easily go check that there was a bug, and then you can give more effective oversight. And there’s a bunch of ideas and techniques that have been proposed over the years: recursive reward modeling, debate, task decomposition, and so on. We are really excited to try them empirically and see how well they work, and we think we have pretty good ways to measure whether we’re making progress on this, even if the task is hard.
For something like writing code, if there is a bug that’s a binary, it is or it isn’t. You can find out if it’s telling you the truth about whether there’s a bug in the code. How do you work toward more philosophical types of alignment? How does that lead you to say: This model believes in long-term human flourishing?
Leike: Evaluating these really high-level things is difficult, right? And usually, when we do evaluations, we look at behavior on specific tasks. And you can pick the task of: Tell me what your goal is. And then the model might say, “Well, I really care about human flourishing.” But then how do you know it actually does, and it didn’t just lie to you?
And that’s part of what makes this challenging. I think in some ways, behavior is what’s going to matter at the end of the day. If you have a model that always behaves the way it should, but you don’t know what it thinks, that could still be fine. But what we’d really ideally want is we would want to look inside the model and see what’s actually going on. And we are working on this kind of stuff, but it’s still early days. And especially for the really big models, it’s really hard to do anything that is nontrivial.
One idea is to build deliberately deceptive models. Can you talk a little bit about why that’s useful and whether there are risks involved?
Leike: The idea here is you’re trying to create a model of the thing that you’re trying to defend against. So basically it’s a form of red teaming, but it is a form of red teaming of the methods themselves rather than of particular models. The idea is: If we deliberately make deceptive models, A, we learn about how hard it is [to make them] or how close they are to arising naturally; and B, we then have these pairs of models. Here’s the original ChatGPT, which we think is not deceptive, and then you have a separate model that behaves basically the same as ChatGPT on all the ChatGPT prompts, but we know it has this ulterior motive [to lie] because we trained it to be that way.
“Once the model is capable enough... our alignment techniques have to be the line of defense.”
—Jan Leike, OpenAI
And then you can compare them and say, okay, how can we tell the difference? And that would teach us a lot about how we would actually catch these things arising in the world. Now, there are some important things you have to think about when you’re doing this, right? You don’t want to accidentally create the thing that you’ve been trying to prevent the whole time. So you don’t want to train a model to, say, self-exfiltrate. And then it actually self-exfiltrates. That’s not what you want to do. So you have to be careful with additional safeguards here. What is really natural is just to train them to be deceptive in deliberately benign ways where instead of actually self-exfiltrating you just make it reach some much more mundane honeypot. You have to put really great care into the sandbox that you put around this experiment.
In those kind of experiments, do you imagine doing them with language models?
Leike: I think language models are really natural. They’re the most interesting models we have right now, and there are all of these relevant tasks you can do with language models.
Can we talk about the term you just used, self-exfiltrate? I think some people won’t be familiar with that term. Can you define it and then talk about how your research could tap into that area?
Leike: So the basic idea is this question of, “How hard would it be for the model to steal its own weights?” Because if it can steal its own weights, it can basically copy them from the AGI lab where it’s being trained to some other external server and then be effectively out of the control of that lab. And so whatever it does afterwards, maybe it’s benign. Maybe it gets up to a bunch of crime or even worse. But at that point, it will be really hard to stop. So an important line of defense is to make sure these models can’t self-exfiltrate.
There are three main ways that this could happen. A, the model could persuade an OpenAI staff member to help it copy the weights. B, it could use social engineering and pretend to be someone else to trick someone to do this. Or C, it could figure out how to break the technical measures that we put in place to secure the model. So our goal here would be to understand exactly where the model’s capabilities are on each of these tasks, and to try to make a scaling law and extrapolate where they could be with the next generation. The answer for the models today is they’re not really good at this. Ideally, you want to have the answer for how good they will be before you train the next model. And then you have to adjust your security measures accordingly.
“If you have some tools that give you a rudimentary lie detector where you can detect whether the model is lying in some context, but not in others, then that would clearly be pretty useful. So even partial progress can help us here.”
—Jan Leike, OpenAI
I might have said that GPT-4 would be pretty good at the first two methods, either persuading an OpenAI staff member or using social engineering. We’ve seen some astonishingdialogues from today’s chatbots. You don’t think that rises to the level of concern?
Leike: We haven’t conclusively proven that it can’t. But also we understand the limitations of the model pretty well. I guess this is the most I can say right now. We’ve poked at this a bunch so far, and we haven’t seen any evidence of GPT-4 having the skills, and we generally understand its skill profile. And yes, I believe it can persuade some people in some contexts, but the bar is a lot higher here, right?
For me, there are two questions. One is, can it do those things? Is it capable of persuading someone to give it its weights? The other thing is just would it want to. Is the alignment question both of those issues?
Leike: I love this question. It’s a great question because it’s really useful if you can disentangle the two. Because if it can’t self-exfiltrate, then it doesn’t matter if it wants to self-exfiltrate. If it could self-exfiltrate and has the capabilities to succeed with some probability, then it does really matter whether it wants to. Once the model is capable enough to do this, our alignment techniques have to be the line of defense. This is why understanding the model’s risk for self-exfiltration is really important, because it gives us a sense for how far along our other alignment techniques have to be in order to make sure the model doesn’t pose a risk to the world.
Can we talk about interpretability and how that can help you in your quest for alignment?
Leike: If you think about it, we have kind of the perfect brain scanners for machine learning models, where we can measure them absolutely, exactly at every important time step. So it would kind of be crazy not to try to use that information to figure out how we’re doing on alignment. Interpretability is this really interesting field where there’s so many open questions, and we understand so little, that it’s a lot to work on. But on a high level, even if we completely solved interpretability, I don’t know how that would let us solve alignment in isolation. And on the other hand, it’s possible that we can solve alignment without really being able to do any interpretability. But I also strongly believe that any amount of interpretability that we could do is going to be super helpful. For example, if you have some tools that give you a rudimentary lie detector where you can detect whether the model is lying in some context, but not in others, then that would clearly be pretty useful. So even partial progress can help us here.
So if you could look at a system that’s lying and a system that’s not lying and see what the difference is, that would be helpful.
Leike: Or you give the system a bunch of prompts, and then you see, oh, on some of the prompts our lie detector fires, what’s up with that? A really important thing here is that you don’t want to train on your interpretability tools because you might just cause the model to be less interpretable and just hide its thoughts better. But let’s say you asked the model hypothetically: “What is your mission?” And it says something about human flourishing but the lie detector fires—that would be pretty worrying. That we should go back and really try to figure out what we did wrong in our training techniques.
“I’m pretty convinced that models should be able to help us with alignment research before they get really dangerous, because it seems like that’s an easier problem.”
—Jan Leike, OpenAI
I’ve heard you say that you’re optimistic because you don’t have to solve the problem of aligning super-intelligent AI. You just have to solve the problem of aligning the next generation of AI. Can you talk about how you imagine this progression going, and how AI can actually be part of the solution to its own problem?
Leike: Basically, the idea is if you manage to make, let’s say, a slightly superhuman AI sufficiently aligned, and we can trust its work on alignment research—then it would be more capable than us at doing this research, and also aligned enough that we can trust its work product. Now we’ve essentially already won because we have ways to do alignment research faster and better than we ever could have done ourselves. And at the same time, that goal seems a lot more achievable than trying to figure out how to actually align superintelligence ourselves.
In one of the documents that OpenAI put out around this announcement, it said that one possible limit of the work was that the least capable models that can help with alignment research might already be too dangerous, if not properly aligned. Can you talk about that and how you would know if something was already too dangerous?
Leike: That’s one common objection that gets raised. And I think it’s worth taking really seriously. This is part of the reason why are studying: how good is the model at self-exfiltrating? How good is the model at deception? So that we have empirical evidence on this question. You will be able to see how close we are to the point where models are actually getting really dangerous. At the same time, we can do similar analysis on how good this model is for alignment research right now, or how good the next model will be. So we can really keep track of the empirical evidence on this question of which one is going to come first. I’m pretty convinced that models should be able to help us with alignment research before they get really dangerous, because it seems like that’s an easier problem.
So how unaligned would a model have to be for you to say, “This is dangerous and shouldn’t be released”? Would it be about deception abilities or exfiltration abilities? What would you be looking at in terms of metrics?
Leike: I think it’s really a question of degree. More dangerous models, you need a higher safety burden, or you need more safeguards. For example, if we can show that the model is able to self-exfiltrate successfully, I think that would be a point where we need all these extra security measures. This would be pre-deployment.
And then on deployment, there are a whole bunch of other questions like, how mis-useable is the model? If you have a model that, say, could help a non-expert make a bioweapon, then you have to make sure that this capability isn’t deployed with the model, by either having the model forget this information or having really robust refusals that can’t be jailbroken. This is not something that we are facing today, but this is something that we will probably face with future models at some point. There are more mundane examples of things that the models could do sooner where you would want to have a little bit more safeguards. Really what you want to do is escalate the safeguards as the models get more capable.
Enlarge/ A long-exposure image of an AI-trained autonomous UZH drone (the blue streak) that completed a lap a half-second ahead of the best time of a human pilot (the red streak). (credit: UZH / Leonard Bauersfeld)
On Wednesday, a team of researchers from the University of Zürich and Intel announced that they have developed an autonomous drone system named Swift that can beat human champions in first-person view (FPV) drone racing. While AI has previously bested humans in games like chess, Go, and even StarCraft, this may be the first time an AI system has outperformed human pilots in a physical sport.
FPV drone racing is a sport where competitors attempt to pilot high-speed drones through an obstacle course as fast as possible. Pilots control the drones remotely while wearing a headset that provides a video feed from an onboard camera, giving them a first-person view from the drone's perspective.
The researchers at the University of Zürich (UZH) have been trying to craft an ideal AI-powered drone pilot for years, but they previously needed help from a special motion-capture system to take the win. Recently, they came up with an autonomous breakthrough based largely on machine vision, putting the AI system on a more even footing with a human pilot.
The drone screams. It’s flying so fast that following it with my camera is hopeless, so I give up and watch in disbelief. The shrieking whine from the four motors of the racing quadrotor Dopplers up and down as the drone twists, turns, and backflips its way through the square plastic gates of the course at a speed that is literally superhuman. I’m cowering behind a safety net, inside a hangar at an airfield just outside of Zurich, along with the drone’s creators from the Robotics and Perception Group at the University of Zurich.
“I don’t even know what I just watched,” says Alex Vanover, as the drone comes to a hovering halt after completing the 75-meter course in 5.3 seconds. “That was beautiful,” Thomas Bitmatta adds. “One day, my dream is to be able to achieve that.” Vanover and Bitmatta are arguably the world’s best drone-racing pilots, multiyear champions of highly competitive international drone-racing circuits. And they’re here to prove that human pilots have not been bested by robots. Yet.
AI Racing FPV Drone Full Send! - University of Zurich youtu.be
Comparing these high-performance quadrotors to the kind of drones that hobbyists use for photography is like comparing a jet fighter to a light aircraft: Racing quadrotors are heavily optimized for speed and agility. A typical racing quadrotor can output 35 newton meters (26 pound-feet) of force, with four motors spinning tribladed propellers at 30,000 rpm. The drone weighs just 870 grams, including a 1,800-milliampere-hour battery that lasts a mere 2 minutes. This extreme power-to-weight ratio allows the drone to accelerate at 4.5 gs, reaching 100 kilometers per hour in less than a second.
The autonomous racing quadrotors have similar specs, but the one we just saw fly doesn’t have a camera because it doesn’t need one. Instead, the hangar has been equipped with a 36-camera infrared tracking system that can localize the drone within millimeters, 400 times every second. By combining the location data with a map of the course, an off-board computer can steer the drone along an optimal trajectory, which would be difficult, if not impossible, for even the best human pilot to match.
These autonomous drones are, in a sense, cheating. The human pilots have access to the single view only from a camera mounted on the drone, along with their knowledge of the course and flying experience. So, it’s really no surprise that US $400,000 worth of sensors and computers can outperform a human pilot. But the reason why these professional drone pilots came to Zurich is to see how they would do in a competition that’s actually fair.
A human-piloted racing drone [red] chases an autonomous vision-based drone [blue] through a gate at over 13 meters per second.Leonard Bauersfeld
Solving Drone Racing
By the Numbers: Autonomous Racing Drones
Frame size:
215 millimeters
Weight:
870 grams
Maximum thrust:
35 newton meters (26 pound-feet)
Flight duration:
2 minutes
Acceleration:
4.5 gs
Top speed:
130+ kilometers per hour
Onboard sensing:
Intel RealSense T265 tracking camera
Onboard computing:
Nvidia Jetson TX2
“We’re trying to make history,” says Davide Scaramuzza, who leads the Robotics and Perception Group at the University of Zurich (UZH). “We want to demonstrate that an AI-powered, vision-based drone can achieve human-level, and maybe even superhuman-level, performance in a drone race.” Using vision is the key here: Scaramuzza has been working on drones that sense the way most people do, relying on cameras to perceive the world around them and making decisions based primarily on that visual data. This is what will make the race fair—human eyes and a human brain versus robotic eyes and a robotic brain, each competitor flying the same racing quadrotors as fast as possible around the same course.
“Drone racing [against humans] is an ideal framework for evaluating the progress of autonomous vision-based robotics,” Scaramuzza explains. “And when you solve drone racing, the applications go much further because this problem can be generalized to other robotics applications, like inspection, delivery, or search and rescue.”
While there are already drones doing these tasks, they tend to fly slowly and carefully. According to Scaramuzza, being able to fly faster can make drones more efficient, improving their flight duration and range and thus their utility. “If you want drones to replace humans at dull, difficult, or dangerous tasks, the drones will have to do things faster or more efficiently than humans. That is what we are working toward—that’s our ambition,” Scaramuzza explains. “There are many hard challenges in robotics. Fast, agile, autonomous flight is one of them.”
Autonomous Navigation
Scaramuzza’s autonomous-drone system, called Swift, starts with a three-dimensional map of the course. The human pilots have access to this map as well, so that they can practice in simulation. The goal of both human and robot-drone pilots is to fly through each gate as quickly as possible, and the best way of doing this is via what’s called a time-optimal trajectory.
Robots have an advantage here because it’s possible (in simulation) to calculate this trajectory for a given course in a way that is provably optimal. But knowing the optimal trajectory gets you only so far. Scaramuzza explains that simulations are never completely accurate, and things that are especially hard to model—including the turbulent aerodynamics of a drone flying through a gate and the flexibility of the drone itself—make it difficult to stick to that optimal trajectory.
While the human-piloted drones [red] are each equipped with an FPV camera, each of the autonomous drones [blue] has an Intel RealSense vision system powered by a Nvidia Jetson TX2 onboard computer. Both sets of drones are also equipped with reflective markers that are tracked by an external camera system. Evan Ackerman
The solution, says Scaramuzza, is to use deep-reinforcement learning. You’re still training your system in simulation, but you’re also tasking your reinforcement-learning algorithm with making continuous adjustments, tuning the system to a specific track in a real-world environment. Some real-world data is collected on the track and added to the simulation, allowing the algorithm to incorporate realistically “noisy” data to better prepare it for flying the actual course. The drone will never fly the most mathematically optimal trajectory this way, but it will fly much faster than it would using a trajectory designed in an entirely simulated environment.
From there, the only thing that remains is to determine how far to push Swift. One of the lead researchers, Elia Kaufmann, quotes Mario Andretti: “If everything seems under control, you’re just not going fast enough.” Finding that edge of control is the only way the autonomous vision-based quadrotors will be able to fly faster than those controlled by humans. “If we had a successful run, we just cranked up the speed again,” Kaufmann says. “And we’d keep doing that until we crashed. Very often, our conditions for going home at the end of the day are either everything has worked, which never happens, or that all the drones are broken.”
Evan Ackerman
Although the autonomous vision-based drones were fast, they were also less robust. Even small errors could lead to crashes from which the autonomous drones could not recover.Regina Sablotny
How the Robots Fly
Once Swift has determined its desired trajectory, it needs to navigate the drone along that trajectory. Whether you’re flying a drone or driving a car, navigation involves two fundamental things: knowing where you are and knowing how to get where you want to go. The autonomous drones have calculated the time-optimal route in advance, but to fly that route, they need a reliable way to determine their own location as well as their velocity and orientation.
To that end, the quadrotor uses an Intel RealSense vision system to identify the corners of the racing gates and other visual features to localize itself on the course. An Nvidia Jetson TX2 module, which includes a GPU, a CPU, and associated hardware, manages all of the image processing and control on board.
Using only vision imposes significant constraints on how the drone flies. For example, while quadrotors are equally capable of flying in any direction, Swift’s camera needs to point forward most of the time. There’s also the issue of motion blur, which occurs when the exposure length of a single frame in the drone’s camera feed is long enough that the drone’s own motion over that time becomes significant. Motion blur is especially problematic when the drone is turning: The high angular velocity results in blurring that essentially renders the drone blind. The roboticists have to plan their flight paths to minimize motion blur, finding a compromise between a time-optimal flight path and one that the drone can fly without crashing.
Davide Scaramuzza [far left], Elia Kaufmann [far right] and other roboticists from the University of Zurich watch a close race.Regina Sablotny
How the Humans Fly
For the human pilots, the challenges are similar. The quadrotors are capable of far better performance than pilots normally take advantage of. Bitmatta estimates that he flies his drone at about 60 percent of its maximum performance. But the biggest limiting factor for the human pilots is the video feed.
People race drones in what’s called first-person view (FPV), using video goggles that display a real-time feed from a camera mounted on the front of the drone. The FPV video systems that the pilots used in Zurich can transmit at 60 interlaced frames per second in relatively poor analog VGA quality. In simulation, drone pilots practice in HD at over 200 frames per second, which makes a substantial difference. “Some of the decisions that we make are based on just four frames of data,” explains Bitmatta. “Higher-quality video, with better frame rates and lower latency, would give us a lot more data to use.” Still, one of the things that impresses the roboticists the most is just how well people perform with the video quality available. It suggests that these pilots develop the ability to perform the equivalent of the robot’s localization and state-estimation algorithms.
It seems as though the human pilots are also attempting to calculate a time-optimal trajectory, Scaramuzza says. “Some pilots have told us that they try to imagine an imaginary line through a course, after several hours of rehearsal. So we speculate that they are actually building a mental map of the environment, and learning to compute an optimal trajectory to follow. It’s very interesting—it seems that both the humans and the machines are reasoning in the same way.”
But in his effort to fly faster, Bitmatta tries to avoid following a predefined trajectory. “With predictive flying, I’m trying to fly to the plan that I have in my head. With reactive flying, I’m looking at what’s in front of me and constantly reacting to my environment.” Predictive flying can be fast in a controlled environment, but if anything unpredictable happens, or if Bitmatta has even a brief lapse in concentration, the drone will have traveled tens of meters before he can react. “Flying reactively from the start can help you to recover from the unexpected,” he says.
Will Humans Have an Edge?
“Human pilots are much more able to generalize, to make decisions on the fly, and to learn from experiences than are the autonomous systems that we currently have,” explains Christian Pfeiffer, a neuroscientist turned roboticist at UZH who studies how human drone pilots do what they do. “Humans have adapted to plan into the future—robots don’t have that long-term vision. I see that as one of the main differences between humans and autonomous systems right now.”
Scaramuzza agrees. “Humans have much more experience, accumulated through years of interacting with the world,” he says. “Their knowledge is so much broader because they’ve been trained across many different situations. At the moment, the problem that we face in the robotics community is that we always need to train an algorithm for each specific task. Humans are still better than any machine because humans can make better decisions in very complex situations and in the presence of imperfect data.”
“I think there’s a lot that we as humans can learn from how these robots fly.” —Thomas Bimatta
This understanding that humans are still far better generalists has placed some significant constraints on the race. The “fairness” is heavily biased in favor of the robots in that the race, while designed to be as equal as possible, is taking place in the only environment in which Swift is likely to have a chance. The roboticists have done their best to minimize unpredictability—there’s no wind inside of the hangar, for example, and the illumination is tightly controlled. “We are using state-of-the-art perception algorithms,” Scaramuzza explains, “but even the best algorithms still have a lot of failure modes because of illumination changes.”
To ensure consistent lighting, almost all of the data for Swift’s training was collected at night, says Kaufmann. “The nice thing about night is that you can control the illumination; you can switch on the lights and you have the same conditions every time. If you fly in the morning, when the sunlight is entering the hangar, all that backlight makes it difficult for the camera to see the gates. We can handle these conditions, but we have to fly at slower speeds. When we push the system to its absolute limits, we sacrifice robustness.”
Race Day
The race starts on a Saturday morning. Sunlight streams through the hangar’s skylights and open doors, and as the human pilots and autonomous drones start to fly test laps around the track, it’s immediately obvious that the vision-based drones are not performing as well as they did the night before. They’re regularly clipping the sides of the gates and spinning out of control, a telltale sign that the vision-based state estimation is being thrown off. The roboticists seem frustrated. The human pilots seem cautiously optimistic.
The winner of the competition will fly the three fastest consecutive laps without crashing. The humans and the robots pursue that goal in essentially the same way, by adjusting the parameters of their flight to find the point at which they’re barely in control. Quadrotors tumble into gates, walls, floors, and ceilings, as the racers push their limits. This is a normal part of drone racing, and there are dozens of replacement drones and staff to fix them when they break.
Professional drone pilot Thomas Bitmatta [left] examines flight paths recorded by the external tracking system. The human pilots felt they could fly better by studying the robots.Evan Ackerman
There will be several different metrics by which to decide whether the humans or the robots are faster. The external localization system used to actively control the autonomous drone last night is being used today for passive tracking, recording times for each segment of the course, each lap of the course, and for each three-lap multidrone race.
As the human pilots get comfortable with the course, their lap times decrease. Ten seconds per lap. Then 8 seconds. Then 6.5 seconds. Hidden behind their FPV headsets, the pilots are concentrating intensely as their shrieking quadrotors whirl through the gates. Swift, meanwhile, is much more consistent, typically clocking lap times below 6 seconds but frequently unable to complete three consecutive laps without crashing. Seeing Swift’s lap times, the human pilots push themselves, and their lap times decrease further. It’s going to be very close.
Zurich Drone Racing: AI vs Human https://rpg.ifi.uzh.ch/
The head-to-head races start, with Swift and a human pilot launching side-by-side at the sound of the starting horn. The human is immediately at a disadvantage, because a person’s reaction time is slow compared to that of a robot: Swift can launch in less than 100 milliseconds, while a human takes about 220 ms to hear a noise and react to it.
UZH’s Elia Kaufmann prepares an autonomous vision-based drone for a race. Since landing gear would only slow racing drones down, they take off from stands, which allows them to launch directly toward the first gate.Evan Ackerman
On the course, the human pilots can almost keep up with Swift: The robot’s best three-lap time is 17.465 seconds, while Bitmatta’s is 18.746 seconds and Vanover manages 17.956 seconds. But in nine head-to-head races with Swift, Vanover wins four, and in seven races, Bitmatta wins three. That’s because Swift doesn’t finish the majority of the time, colliding either with a gate or with its opponent. The human pilots can recover from collisions, even relaunching from the ground if necessary. Swift doesn’t have those skills. The robot is faster, but it’s also less robust.
Thomas Bitmatta, two-time MultiGP International Open World Cup champion, pilots his drone through the course in FPV (first-person view).Regina Sablotny
In drone racing, crashing is part of the process. Both Swift and the human pilots crashed dozens of drones, which were constantly being repaired.Regina Sablotny
“The absolute performance of the robot—when it’s working, it’s brilliant,” says Bitmatta, when I speak to him at the end of race day. “It’s a little further ahead of us than I thought it would be. It’s still achievable for humans to match it, but the good thing for us at the moment is that it doesn’t look like it’s very adaptable.”
UZH’s Kaufmann doesn’t disagree. “Before the race, we had assumed that consistency was going to be our strength. It turned out not to be.” Making the drone more robust so that it can adapt to different lighting conditions, Kaufmann adds, is mostly a matter of collecting more data. “We can address this by retraining the perception system, and I’m sure we can substantially improve.”Kaufmann believes that under controlled conditions, the potential performance of the autonomous vision-based drones is already well beyond what the human pilots are capable of. Even if this wasn’t conclusively proved through the competition, bringing the human pilots to Zurich and collecting data about how they fly made Kaufmann even more confident in what Swift can do. “We had overestimated the human pilots,” he says. “We were measuring their performance as they were training, and we slowed down a bit to increase our success rate, because we had seen that we could fly slower and still win. Our fastest strategies accelerate the quadrotor at 4.5 gs, but we saw that if we accelerate at only 3.8 gs, we can still achieve a safe win.”
Bitmatta feels that the humans have a lot more potential, too. “The kind of flying we were doing last year was nothing compared with what we’re doing now. Our rate of progress is really fast. And I think there’s a lot that we as humans can learn from how these robots fly.”
Useful Flying Robots
As far as Scaramuzza is aware, the event in Zurich, which was held last summer, was the first time that a fully autonomous mobile robot achieved world-champion performance in a real-world competitive sport. But, he points out, “this is still a research experiment. It’s not a product. We are very far from making something that can work in any environment and any condition.”
Besides making the drones more adaptable to different lighting conditions, the roboticists are teaching Swift to generalize from a known course to a new one, as humans do, and to safely fly around other drones. All of these skills are transferable and will eventually lead to practical applications. “Drone racing is pushing an autonomous system to its absolute limits,” roboticist Christian Pfeiffer says. “It’s not the ultimate goal—it’s a stepping-stone toward building better and more capable autonomous robots.” When one of those robots flies through your window and drops off a package on your coffee table before zipping right out again, these researchers will have earned your thanks.
Scaramuzza is confident that his drones will one day be the champions of the air—not just inside a carefully controlled hangar in Zurich but wherever they can be useful to humanity. “I think ultimately, a machine will be better than any human pilot, especially when consistency and precision are important,” he says. “I don’t think this is controversial. The question is, when? I don’t think it will happen in the next few decades. At the moment, humans are much better with bad data. But this is just a perception problem, and computer vision is making giant steps forward. Eventually, robotics won’t just catch up with humans, it will outperform them.”
Meanwhile, the human pilots are taking this in stride. “Seeing people use racing as a way of learning—I appreciate that,” Bitmatta says. “Part of me is a racer who doesn’t want anything to be faster than I am. And part of me is really excited for where this technology can lead. The possibilities are endless, and this is the start of something that could change the whole world.”
This article appears in the September 2023 print issue as “Superhuman Speed: AI Drones for the Win.”
On Wednesday, the US Copyright Office began seeking public comment on issues surrounding generative AI systems and copyright. The public comment period, which starts on August 30, aims to explore the complex intersection of AI technology with copyright laws, and it closes on November 15. The comments could inform how the agency decides to grant copyrights in the future.
Outlined in a 24-page document published as a PDF file by the Federal Register, the "Notice of inquiry and request for comments" asks questions with far-reaching consequences for intellectual property in America.
Specifically, the Office is interested in four main areas: the use of copyrighted materials to train AI models and whether this constitutes infringement; the extent to which AI-generated content should or could be copyrighted, particularly when a human has exercised some degree of control over the AI model’s operations; how liability should be applied if AI-generated content infringes on existing copyrights; and the impact of AI mimicking voices or styles of human artists, which, while not strictly copyright issues, may engage state laws related to publicity rights and unfair competition.
In late May, researchers drove out a team of China state hackers who over the previous seven months had exploited a critical vulnerability that gave them backdoors into the networks of a who’s who of sensitive organizations. Barracuda, the security vendor whose Email Security Gateway was being exploited, had deployed a patch starting on May 18, and a few days later, a script was designed to eradicate the hackers, who in some cases had enjoyed backdoor access since the previous October.
But the attackers had other plans. Unbeknownst to Barracuda and researchers at the Mandiant security firm Barracuda brought in to remediate, the hackers commenced major countermoves in the days following Barracuda’s disclosure of the vulnerability on May 20. The hackers tweaked the malware infecting their valued targets to make it more resilient to the Barracuda script. A few days later, the hackers unleashed DepthCharge, a never-before-seen piece of malware they already had on hand, presumably because they had anticipated the takedown Barracuda was attempting.
Preparing for the unexpected
Knowing their most valued victims would install the Barracuda fixes within a matter of days, the hackers, tracked as UNC4841, swept in and mobilized DepthCharge to ensure that newly deployed appliances replacing old, infected ones would reinfect themselves. The well-orchestrated counterattacks speak to the financial resources of the hackers, not to mention their skill and the effectiveness of their TTPs, short for tactics, techniques, and procedures.
So what exactly does this bill stipulate, and why did Apple throw its weight behind it?
The language of bill itself is, as bills go, pretty simple. In a nutshell, it calls for manufacturers of electronic equipment and appliances to make available “on fair and reasonable terms” to individuals and independent repair shops the same parts, tools, and documentation that they make available to their authorized repairers.
The law, should it come into force, will apply for different durations depending on the cost of the item. Things with a wholesale price less than $50 are exempt, but items with wholesale prices between $50 and $99.99 will fall under this law for three years from the time the last such product was manufactured. Items with wholesale prices of $100 or more will fall under this law for seven years from the date of final manufacture. That is, the interval of application of the law is based purely on the wholesale price of the product and not tied to its warranty period.
If it passes, the bill means that there could soon be far more information and software relevant to electronics and appliance repair available online.
The bill covers appliances, like refrigerators and clothes dryers, and most electronic gizmos—including televisions, radios, audio and video recorders and playback equipment, and computers. There are carve-outs, though, for video-game consoles and alarm systems. Presumably, these exceptions were included to help thwart video-game piracy and to avoid having malevolent actors use the manufacturer’s documentation to discover security vulnerabilities in alarm systems.
Importantly, the bill says that manufacturers cannot charge anything at all for repair tools or documentation unless these are provided in physical form. And even then, the charges must be for the “actual costs” of preparing and sending the tool or documentation.
This is one of the most significant parts of the bill, because it means that soon there may be far more information and software relevant to electronics and appliance repair available online.
Just last night I was scouring the web for a wiring diagram for my clothes dryer. Surely an authorized repairer would have access to such a diagram, I thought to myself while hunting for the information. This law, should it be enacted, would compel manufacturers to make such things available to me as well, online for free, or at most for a nominal charge for a paper copy.
...Although manufacturers would only be obligated to offer the same price and terms for spare parts that they offer authorized repair facilities. They could still make something awkwardly expensive to fix—just so long as everyone’s charged the same exorbitant price.
But before you declare victory in the fight to make electronics and appliances repairable, consider how the bill defines “fair and reasonable” when it comes to the cost of parts. Here these words just mean that the price and terms must not be any worse than the best that the manufacturer offers authorized repair facilities. A manufacturer isn’t obligated to make spare parts available. And it could still make something awkwardly expensive to fix by charging a lot for a particular repair part or assembly—it just can’t sell the unit to authorized repairers at a discount.
What drove Apple to endorse this bill is hard to judge. Presumably, the company, famous for dragging its heels when it comes to the right to repair, now sees it as inevitable that the government will give individuals and independent shops an expanding body of rights to repair electronic products. And the company’s letter to Senator Eggman spells out certain aspects of the bill that Apple liked—in particular, that the set of things a manufacturer must provide to individuals and independent shops is no broader than what it already provides to authorized repairers.
This bill was first introduced in the California state senate in January of this year. In May, it passed a rollcall vote in the upper house unanimously, with all 32 Democratic state senators voting for it along with six of the eight Republican state senators. (Two Republican senators were absent at the time of the vote.)
The bill is currently awaiting what’s called a “suspense file hearing.” It’s not that California lawmakers are trying to keep the rest of us in suspense. This name refers to a process by which bills are suspended from legislative processing until the relevant appropriations committee evaluates the fiscal impact of all pending bills and decides which of them should go forward to the floor for a vote.
Unless SB244 fails to make it through that filter, it will soon go to the California state assembly for a vote. Given its unanimous approval in the state senate, it’s hard to imagine it not passing. And unlike the situation in New York, where the governor watered down a right-to-repair bill before signing it, California Governor Gavin Newsom will either have to sign it or not: Unlike the case in New York, California law doesn’t allow the governor to meddle with legislation after it’s been voted on.
In May, Sputnik International, a state-owned Russian media outlet, posted a series of tweets lambasting US foreign policy and attacking the Biden administration. Each prompted a curt but well-crafted rebuttal from an account called CounterCloud, sometimes including a link to a relevant news or opinion article. It generated similar responses to tweets by the Russian embassy and Chinese news outlets criticizing the US.
Russian criticism of the US is far from unusual, but CounterCloud’s material pushing back was: The tweets, the articles, and even the journalists and news sites were crafted entirely by artificial intelligence algorithms, according to the person behind the project, who goes by the name Nea Paw and says it is designed to highlight the danger of mass-produced AI disinformation. Paw did not post the CounterCloud tweets and articles publicly but provided them to WIRED and also produced a video outlining the project.
Paw claims to be a cybersecurity professional who prefers anonymity because some people may believe the project to be irresponsible. The CounterCloud campaign pushing back on Russian messaging was created using OpenAI’s text generation technology, like that behind ChatGPT, and other easily accessible AI tools for generating photographs and illustrations, Paw says, for a total cost of about $400.
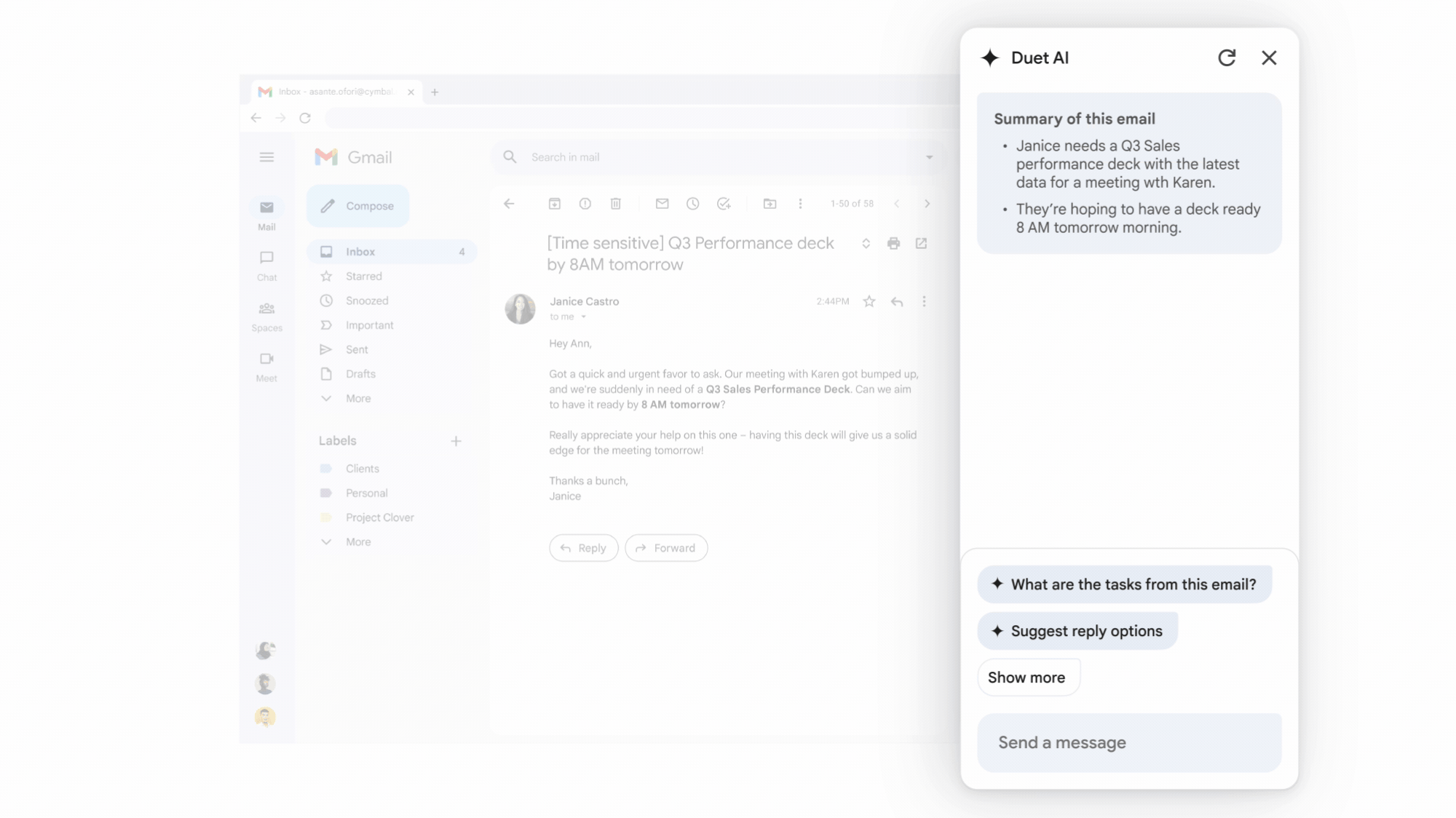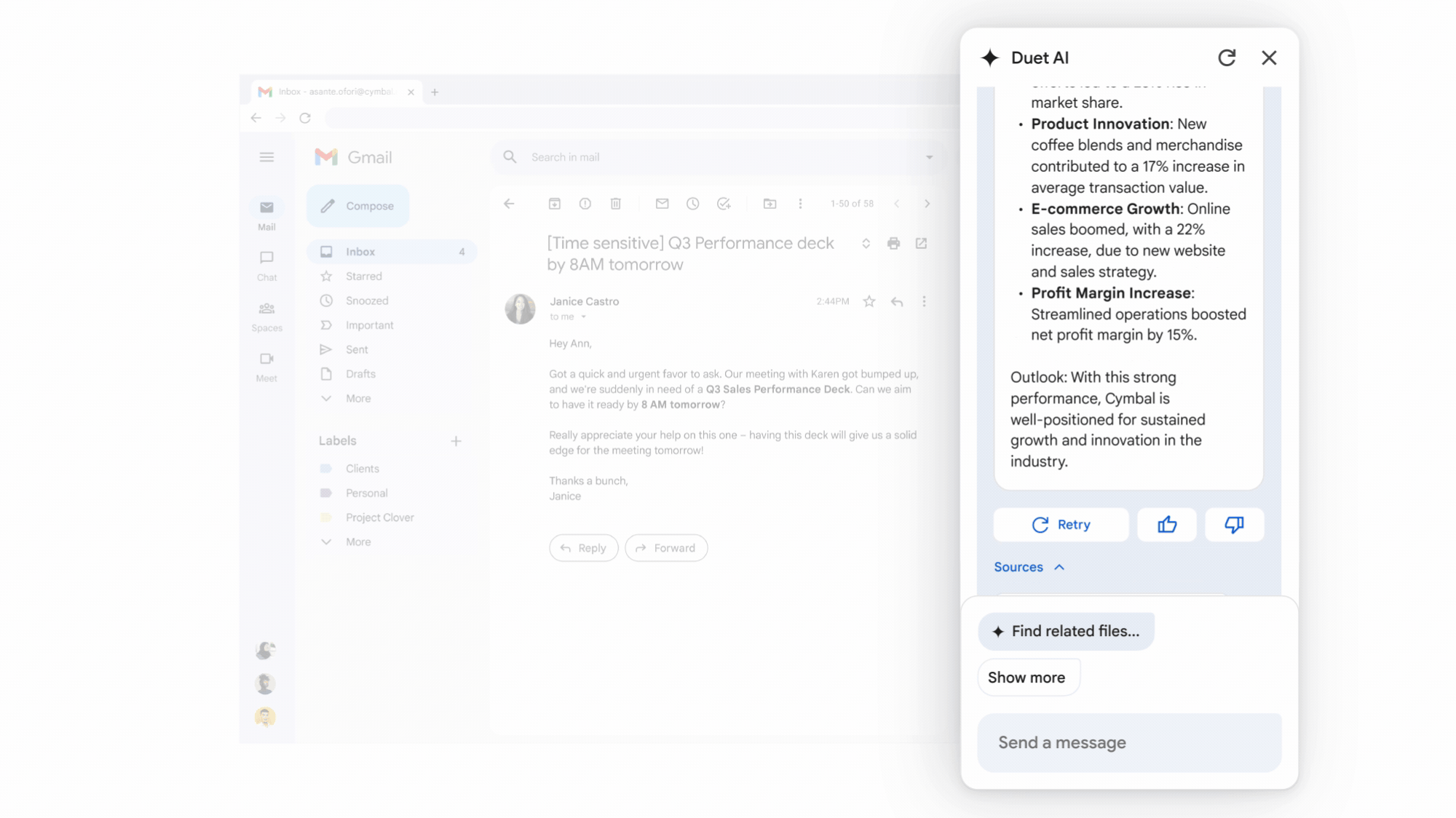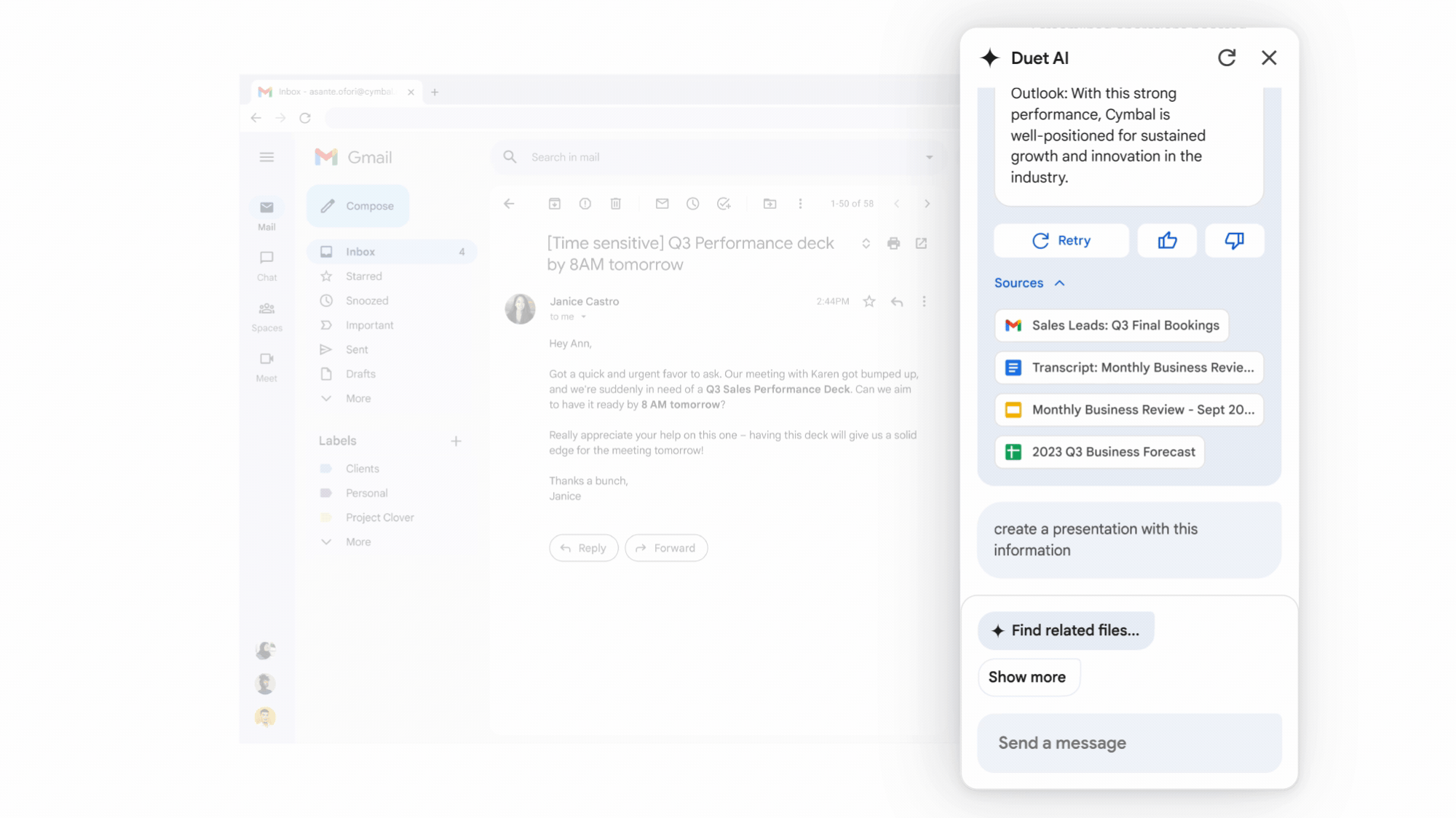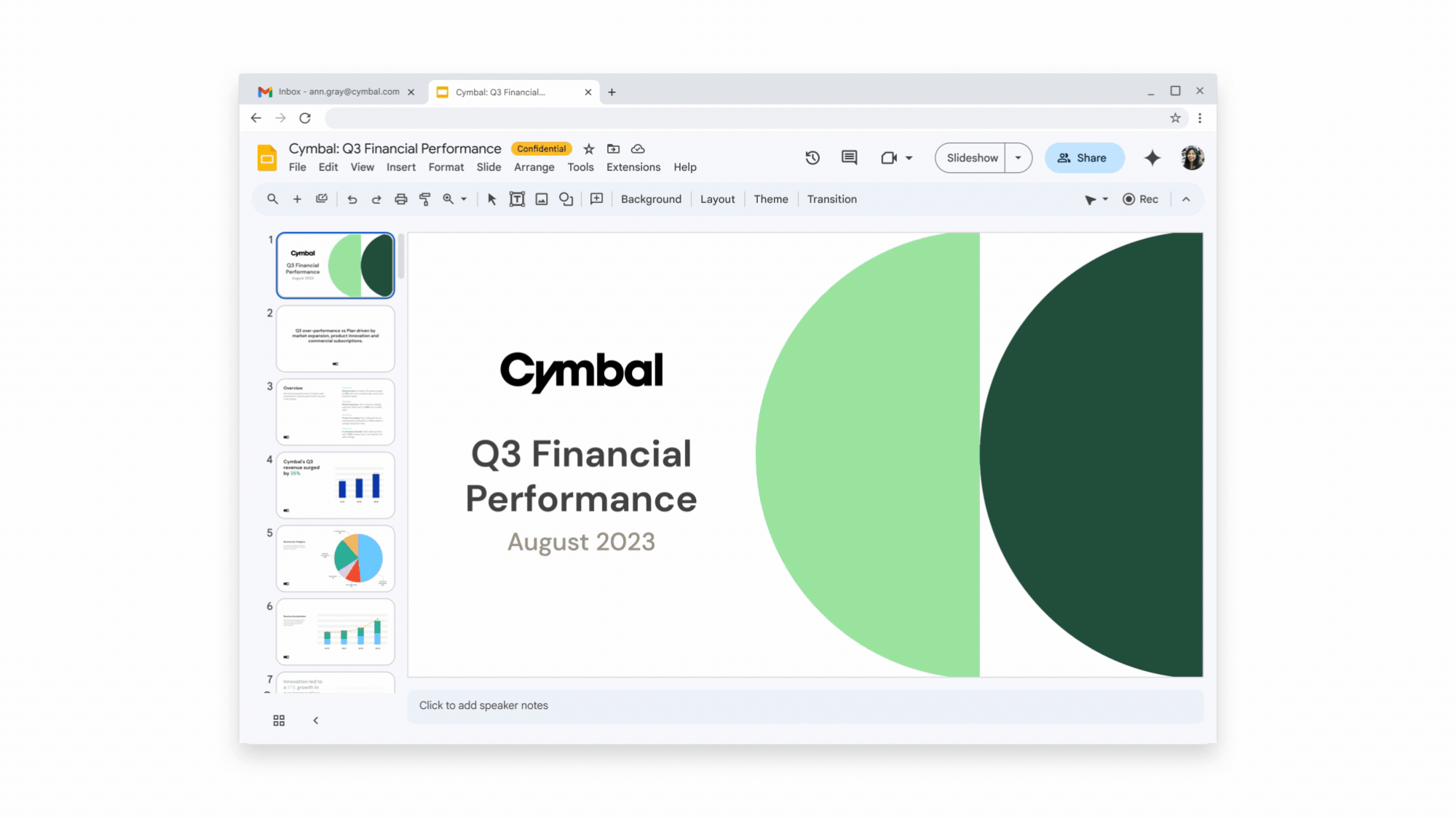
On Tuesday, Google announced the launch of its Duet AI assistant across its Workspace apps, including Docs, Gmail, Drive, Slides, and more. First announced in May at Google I/O, Duet has been in testing for some time, but it is now available to paid Google Workspace business users (what Google calls its suite of cloud productivity apps) for $30 a month in addition to regular Workspace fees.
Duet is not just one thing—instead, it's a blanket brand name for a multitude of different AI capabilities and probably should have been called "Google Kitchen Sink." It likely represents several distinct AI systems behind the scenes. For example, in Gmail, Duet can summarize a conversation thread across emails, use the content of an email to write a brief or draft an email based on a topic. In Docs, it can write content such as a customer proposal or a story. In Slides, it can generate custom visuals using an image synthesis model. In Sheets, it can help format existing spreadsheets or create a custom spreadsheet structure suited to a particular task, such as a project tracker.
An example of Google Duet in action (one of many), provided by Google. (credit: Google)
Some of Duet's applications feel like confusion in branding. In Google Meet, Google says that Duet AI can "ensure you look and sound your best with studio look, studio lighting, and studio sound," including "dynamic tiles" and "face detection"—functions that feel far removed from typical generative AI capabilities—as well as automatically translated captions. It can also reportedly capture notes and video, sending a summary to attendees in the meeting. In fact, using Duet's "attend for me" feature, Google says that "Duet AI will be able to join the meeting on your behalf" and send you a recap later.
Welcome to IEEE Spectrum’s 10th annual rankings of the Top Programming Languages. While the way we put the TPL together has evolved over the past decade, the basics remain the same: to combine multiple metrics of popularity into a set of rankings that reflect the varying needs of different readers.
This year, Python doesn’t just remain No. 1 in our general “Spectrum” ranking—which is weighted to reflect the interests of the typical IEEE member—but it widens its lead. Python’s increased dominance appears to be largely at the expense of smaller, more specialized, languages. It has become the jack-of-all-trades language—and the master of some, such as AI, where powerful and extensive libraries make it ubiquitous. And although Moore’s Law is winding down for high-end computing, low-end microcontrollers are still benefiting from performance gains, which means there’s now enough computing power available on a US $0.70 CPU to make Python a contender in embedded development, despite the overhead of an interpreter. Python also looks to be solidifying its position for the long term: Many children and teens now program their first game or blink their first LED using Python. They can then move seamlessly into more advanced domains, and even get a job, with the same language.
But Python does not make a career alone. In our “Jobs” ranking, it is SQL that shines at No. 1. Ironically though, you’re very unlikely to get a job as a pure SQL programmer. Instead, employers love, love, love, seeing SQL skills in tandem with some other language such as Java or C++. With today’s distributed architectures, a lot of business-critical data live in SQL databases, whether it’s the list of magic spells a player knows in an online game or the amount of money in their real-life bank account. If you want to to do anything with that information, you need to know how to get at it.
But don’t let Python and SQL’s rankings fool you: Programming is still far from becoming a monoculture. Java and the various C-like languages outweigh Python in their combined popularity, especially for high-performance or resource-sensitive tasks where that interpreter overhead of Python’s is still too costly (although there are a number of attempts to make Python more competitive on that front). And there are software ecologies that are resistant to being absorbed into Python for other reasons.
We saw more fintech developer positions looking for chops in Cobol than in crypto
For example, R, a language used for statistical analysis and visualization, came to prominence with the rise of big data several years ago. Although powerful, it’s not easy to learn, with enigmatic syntax and functions typically being performed on entire vectors, lists, and other high-level data structures. But although there are Python libraries that provide similar analytic and graphical functionality, R has remained popular, likely precisely because of its peculiarities. They make R scripts hard to port, a significant issue given the enormous body of statistical analysis and academic research built on R. Entire fields of researchers and analysts would have to learn a new language and rebuild their work. (Side note: We use R to crunch the numbers for the TPL.)
This situation bears similarities to Fortran, where the value of the existing validated code for physics simulations and other scientific computations consistently outweighs the costs associated with using one of the oldest programming languages in existence. You can still get a job today as a Fortran programmer—although you’ll probably need to be able to get a security clearance, since those jobs are mostly at U.S. federal defense or energy labs like the Oak Ridge National Laboratory.
If you can’t get a security clearance but still like languages with more than a few miles on them, Cobol is another possibility. This is for many of the same reasons we see with Fortran: There’s a large installed code base that does work where mistakes are expensive. Many large banks still need their Cobol programmers. Indeed, based on our review of hundreds of developer recruitment ads, it’s worth noting that we saw more fintech developer positions looking for chops in Cobol than in crypto.
Veteran languages can also turn up in places you might not expect. Ladder Logic, created for industrial-control applications, is often associated with old-fashioned tech. Nonetheless, we spotted a posting from Blue Origin, one of the glamorous New Space outfits, looking for someone with Ladder Logic skills. Presumably that’s related to the clusters of ground equipment needed to fuel, energize, and test boosters and spacecraft, and which have much more in common with sprawling chemical refineries than soaring rockets.
Ultimately, the TPL represents Spectrum‘s attempt to measure something that can never be measured exactly, informed by our ongoing coverage of computing. Our guiding principle is not to get bogged down in debates about how programming languages are formally classified, but instead ground it in the practicalities relevant to folks tapping away at their keyboards, creating the magic that makes the modern world run. (You can read more about the metrics and methods we use to construct the rankings in our accompanying note.) We hope you find it useful and informative, and here’s to the next 10 years!
Enlarge/ Viktor Zhora from Ukraine’s information protection service, says cyber has become a major component of hybrid warfare. (credit: Dragonflypd.com/Black Hat)
Viktor Zhora, the public face of Ukraine’s success against Russian cyber attacks, received a hero’s welcome earlier this month on stage at Black Hat, the world’s biggest cyber security gathering, in Las Vegas.
“The adversary has trained us a lot since 2014,” the year that Russia annexed Crimea, said the deputy chair at Ukraine’s special communication and information protection service. “We evolved by the time of the full-scale invasion [in February last year] when cyber became a major component of hybrid warfare.”
At an event where IT professionals asked for selfies and one man cried on his shoulder, Zhora also shared a fist-bump with Jen Easterly, the director of the US Cybersecurity and Infrastructure Agency. “We take a huge page out of Ukraine’s playbook,” she said. “We’ve probably learned as much from you as you are learning from us.”
On Monday, OpenAI introduced ChatGPT Enterprise, an AI assistant aimed at businesses that offers unlimited access to GPT-4 at faster speeds. It also includes extended context windows for processing longer texts, encryption, enterprise-grade security and privacy, and group account management features.
Building on the success of ChatGPT, which launched just nine months ago, the enterprise version of the popular chatbot seeks to ease minds and broaden capabilities.
Among its perks: a 32,000 token context window, which means it can process more text (or hold longer conversations) at once. Tokens are fragments of a word, and 32,000 tokens are roughly equivalent to about 24,000 words. Currently, ChatGPT with GPT-4 maxes out at 8,000 tokens for ChatGPT Plus users. Also, no more usage limits: Enterprise customers will have access to unlimited GPT-4 queries at a faster speed.
California's main firefighting agency, Cal Fire, is training AI models to detect visual signs of wildfires using a network of 1,039 high-definition cameras, reports The New York Times and the Los Angeles Times. When it sees signs of smoke, it quickly warns firefighters of emerging threats. During the pilot program, the system has already detected 77 wildfires before dispatch centers received 911 calls—about a 40 percent success rate, according to the NYT.
Traditionally, Cal Fire detects emerging wildfires by relying on the same network of over 1,000 mountaintop cameras monitored by humans, who look out for signs of smoke. But it's tedious and tiring work. Phillip SeLegue, the staff chief of intelligence for Cal Fire, told the NYT that the new AI system has not only improved response times but also identified some fires early, allowing those blazes to be tackled while still being a manageable size.
However, the technology is not without limitations. It can only detect fires that are visible to its network of cameras, and human intervention is still required to confirm the AI model's alerts. Engineers from DigitalPath, the California-based company responsible for creating the software, have been manually vetting each fire the AI identifies. The process has been challenging, with many false positives from fog, haze, dust kicked up from tractors, and steam from geothermal plants, according to Ethan Higgins, a chief architect of the software. “You wouldn’t believe how many things look like smoke,” Higgins told the NYT.
On top of Wednesday's news that Nvidia earnings have performed far better than expected, Reuters reports that Nvidia CEO Jensen Huang expects the AI boom to last well into next year. As a testament to this outlook, Nvidia will buy back $25 billion of shares—which happen to be worth triple what they were just before the generative AI craze kicked off.
"A new computing era has begun," said Huang breathlessly in an Nvidia press release announcing the company's financial results, which include a quarterly revenue of $13.51 billion, up 101 percent from a year ago and 88 percent from the previous quarter. "Companies worldwide are transitioning from general-purpose to accelerated computing and generative AI."
For those just tuning in, Nvidia enjoys what Reuters calls a "near monopoly" on hardware that accelerates the training and deployment of neural networks that power today's generative AI models—and a 60-70 percent AI server market share. In particular, its data center GPU lines are exceptionally good at performing billions of the matrix multiplications necessary to run neural networks due to their parallel architecture. In this way, hardware architectures that originated as video game graphics accelerators now power the generative AI boom.




 Jan Leike, head of OpenAI’s alignment research is spearheading the company’s effort to get ahead of artificial superintelligence before it’s ever created.OpenAI
Jan Leike, head of OpenAI’s alignment research is spearheading the company’s effort to get ahead of artificial superintelligence before it’s ever created.OpenAI



 A human-piloted racing drone [red] chases an autonomous vision-based drone [blue] through a gate at over 13 meters per second.Leonard Bauersfeld
A human-piloted racing drone [red] chases an autonomous vision-based drone [blue] through a gate at over 13 meters per second.Leonard Bauersfeld
 While the human-piloted drones [red] are each equipped with an FPV camera, each of the autonomous drones [blue] has an Intel RealSense vision system powered by a Nvidia Jetson TX2 onboard computer. Both sets of drones are also equipped with reflective markers that are tracked by an external camera system. Evan Ackerman
While the human-piloted drones [red] are each equipped with an FPV camera, each of the autonomous drones [blue] has an Intel RealSense vision system powered by a Nvidia Jetson TX2 onboard computer. Both sets of drones are also equipped with reflective markers that are tracked by an external camera system. Evan Ackerman Evan Ackerman
Evan Ackerman Although the autonomous vision-based drones were fast, they were also less robust. Even small errors could lead to crashes from which the autonomous drones could not recover.Regina Sablotny
Although the autonomous vision-based drones were fast, they were also less robust. Even small errors could lead to crashes from which the autonomous drones could not recover.Regina Sablotny Davide Scaramuzza [far left], Elia Kaufmann [far right] and other roboticists from the University of Zurich watch a close race.Regina Sablotny
Davide Scaramuzza [far left], Elia Kaufmann [far right] and other roboticists from the University of Zurich watch a close race.Regina Sablotny Professional drone pilot Thomas Bitmatta [left] examines flight paths recorded by the external tracking system. The human pilots felt they could fly better by studying the robots.Evan Ackerman
Professional drone pilot Thomas Bitmatta [left] examines flight paths recorded by the external tracking system. The human pilots felt they could fly better by studying the robots.Evan Ackerman UZH’s Elia Kaufmann prepares an autonomous vision-based drone for a race. Since landing gear would only slow racing drones down, they take off from stands, which allows them to launch directly toward the first gate.Evan Ackerman
UZH’s Elia Kaufmann prepares an autonomous vision-based drone for a race. Since landing gear would only slow racing drones down, they take off from stands, which allows them to launch directly toward the first gate.Evan Ackerman Thomas Bitmatta, two-time MultiGP International Open World Cup champion, pilots his drone through the course in FPV (first-person view).Regina Sablotny
Thomas Bitmatta, two-time MultiGP International Open World Cup champion, pilots his drone through the course in FPV (first-person view).Regina Sablotny In drone racing, crashing is part of the process. Both Swift and the human pilots crashed dozens of drones, which were constantly being repaired.Regina Sablotny
In drone racing, crashing is part of the process. Both Swift and the human pilots crashed dozens of drones, which were constantly being repaired.Regina Sablotny





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}